Технологии быстрой BI аналитики
Тормозит живая стыковка с большими данными?
Заметили, что обновление серверов не повышает производительность приложений, как это было раньше?
Сложно ли вам масштабировать текущее BI решение в ответ на рост пользователей, объёмов данных и аналитических задач?
Пользователи ждут по 10 секунд и больше, чтобы просто открыть дэшборд?
Хотите использовать широкие аналитические возможности, доступные внутри современных баз данных?
Датацентричный Business Intelligence
Запредельные объёмы информации приводят к медленной работе BI систем на всех этапах: от стыковки с источниками до визуализации. Чтобы гарантировать непревзойдённую скорость на любых наборах данных при разработке BI мы воплотили датацентричный технологический подход:
Сервер приложений в СУБД + Три слоя хранения + Вычисления ближе к данным
Сервер приложений в СУБД
Главная задача BI – помогать извлекать полезную информацию из данных для эффективного управления. Здесь нужен современный инфраструктурный фундамент, где данные и приложения первичны, а технологии, разрабатываемые для них, — вторичны. Сервер приложений Luxms BI размещён внутри базы данных, что позволяет перенести фокус с бизнес-логики на сами цифры. В отличие от большинства систем бизнес-анализа наша платформа не тратит время на выборку данных в локальную базу.
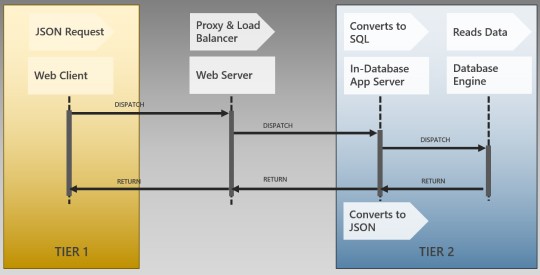
Минимизируется трафик на сети. Нет лишних шагов по переносу информации, поэтому Luxms BI справляется практически с неограниченными объёмами. В полной мере могут быть использованы возможности СУБД по аналитической обработке. Наша локальная база – PostgreSQL. Для работы с большими данными мы можем подключить массивно-параллельные базы: Greenplum, Oracle Exadata, Arenadata, Clickhouse.
Три слоя хранения
Мы выделяем три слоя данных для BI анализа: горячие, тёплые и холодные.
Горячие данные нужны постоянно и оперативно. Пример: показатели работоспособности ИТ систем. Должны быть доступны онлайн.
Тёплые данные нужны часто, но не срочно. Небольшая задержка не критична. Пример: доходы и расходы компании за месяц. Запрашиваются для подготовки регулярной отчётности.
Холодные данные нужны редко и не срочно. Пример: данные об активах за последние 10 лет. Зачастую просто накапливаются в архивах.
Для каждого слоя система бизнес-аналитики использует свои технологии обработки и хранения. Мы разработали следующий конвейер обработки входящей информации.
Данные из транзакционных систем поступают в брокер очередей, где разделяются на отдельные потоки. Затем они попадают в потоковый процессор, где анализируются на лету. Результаты анализа размещаются в соответствующие слои хранения: горячий, тёплый или холодный.
Горячие данные хранятся в памяти. Мы рекомендуем использовать Apache Dremio. Тёплые данные хранятся в массивно-параллельной СУБД, такой как Greenplum, Oracle Exadata, ClickHouse. Холодные данные попадают в хранилище на базе Hadoop. Со временем данные перемещаются между слоями: горячие становятся тёплыми, тёплые переходят в холодные. На горячих данных Luxms BI строит оперативную, потоковую бизнес-аналитику BI в режиме, близком к реальному времени. На тёплых и холодных данных настраивается классическая отчётность и Big Data аналитика.
Вычисления ближе к данным
Взаимодействие Business Intelligence системы и базы данных происходит за доли секунды через функцию Push Down.
Мы сделали высокоскоростной двунаправленный нативный коннектор FDW, который позволяет представлять таблицы, физически хранящиеся в СУБД, как локальные таблицы PostgreSQL. Взаимодействие Business Intelligence системы и базы данных происходит на лету через функцию Push Down. Платформа делегирует исполнение сложных аналитических запросов в СУБД и в онлайн режиме визуализирует полученный результат. Данные не копируются, поэтому нет проблемы кэширования на клиенте. Анализ данных в BI происходит на исходных данных, размещенных в СУБД, что снимает вопросы достоверности. Ограничений на одновременное использование локальных и внешних данных для построения визуализаций нет.
Для остальных источников данных, доступных по JDBC, используется внутренний компонент Datagate, который, как и FDW коннектор, позволяет выполнять онлайн запросы.