13 Книга рецептов
Инициализация свойств для потока
inject отправляет сообщение в поток вручную или через равные промежутки времени. Данные в сообщении могут быть различных типов, включая строку, числа, логические значения, объекты JavaScript, значения потоковых/глобальных контекстов или метку текущего времени, которая является текущим временем в миллисекундах, прошедших с 1 января 1970 года.
Создадим простейший поток с использованием inject:

Рассмотрим пример с включенными сообщениями строки, числа, логического значения и метки времени при ежедневном повторении в 12:00:
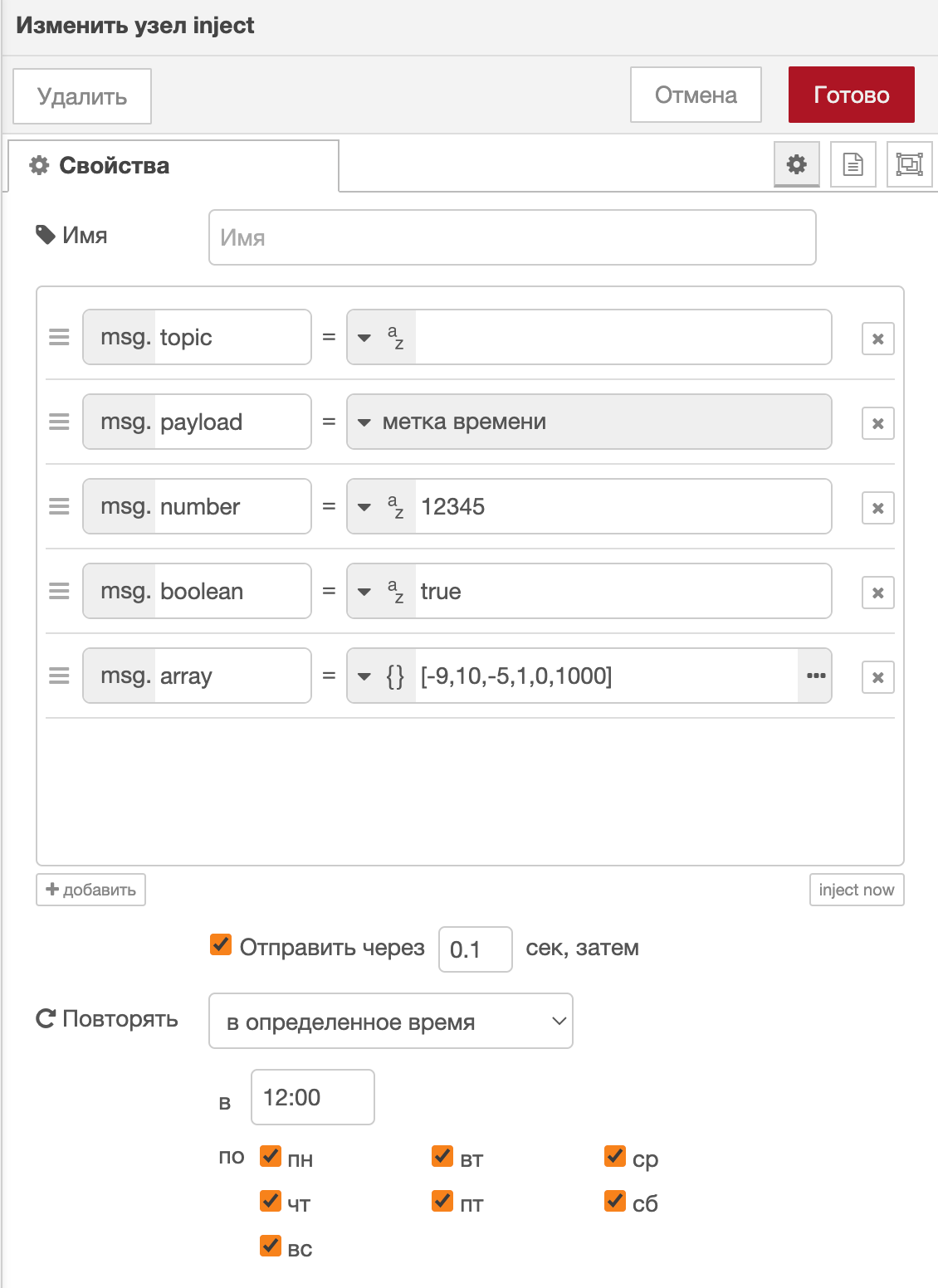
В результате запуска узла получим следующий ответ:
По умолчанию узел запускается вручную по нажатии на кнопку в редакторе. Его также можно настроить на автоматический запуск с интервалом через равные промежутки времени или по расписанию в определённые дни и в определённое время.
Код потока Initializing properties for a stream
Планировщик задач
Данный узел предназначен для управления периодическим запуском потока. Предоставляет более глубокие возможности, нежели inject.
В шаблон узла можно вписывать любую конфигурацию cron.

В данном примере используем данную конфигурацию: 16 8,10,12,14,16,18 * * * - которая означает, что данный узел отдаст команду на старт потока в 16 минут в 9,11,13,15,17,19 часов ежедневно и ежемесячно.
В данном примере используем простой запрос 1 из базы.
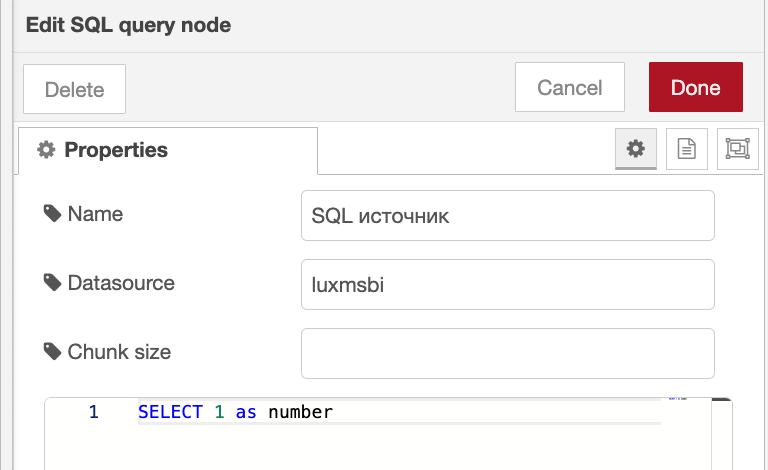
В результате получаем следующий ответ:
Планировщик задачВ связи с некоторыми ограничениями, которые на данный момент не разрешены, сам запрос может запускаться до 2 минут позже выбранной минуты, но при этом периодичность запуска остаётся точной, то есть при данной конфигурации запрос может отратработать в 9:18 (9:17:29 в нашем случае), а не в 9:16 ровно, но при этом следующий запрос так же отработает в 11:18 (11:17:29).
Код потока Task Scheduler
Отслеживание изменений в папке
Узел watch предназначен для отслеживания изменений действий с определенным файлом, может являться триггером для запуска потока.
В данном примере рассмотрим простейший поток для общего понимания работы узла.

watch“Нацелим” наш watch на файл Data.xslx, находящийся в папке /tmp/:
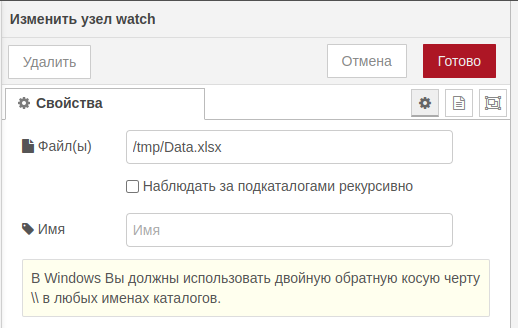
watchПри любом изменении файла (удаление, создание, обновление) мы будем получать сообщение от данного узла.
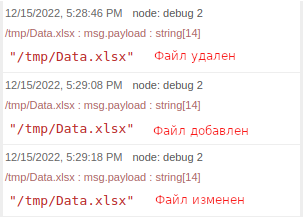
watchВнедрение узла watch очень удобно при перезаписи какого-либо файла, являющегося источником данных или справочником. То есть, можно после данного узла поставить узлы Импорт файлов - который прогрузит файл в базу, а затем SQL источник, который запустит соответствующие скрипты, для обновления данных в кубах. В результате получим поток, который самостоятельно обновит данные при появлении обновлений.
При этом нужно помнить, что при удалении файла данный узел так же подаст сигнал на исполнение потока, в связи с чем стоит производить дополнительные проверки, чтобы отсутствие файла не привело к потере отображаемых данных.
Код потока Tracking changes in a folder
SQL источник / Выполнить произвольный запрос на сервере
Узлы SQL источник и Выполнить произвольный запрос на сервере выполняют схожую функцию - запросы к базе данных, подключенной к данному контуру. Однако у них есть одно существенное отличие - SQL источник обязательно ожидает какой-то ответ после запроса, в то время как Выполнить произвольный запрос на сервере наоборот, работает только когда запрос ничего не возвращает (например процедуры или функции возвращающие void).
Рассмотрим несколько примеров на основании простейшего потока:

SQL источникВ запрос узла пропишем запрос SELECT 1;.
В результате получаем следующий ответ:
SQL источник запроса 1Также можно передавать свойства, определённые в узле function, на вход узлу SQL источник.
msg.number = 1;
return msg;
В самом узле SQL источник в запросе необходимо указать, какое свойство принимается на вход.
select ${msg.number} as nm
Код потока SQL source 1
Либо в самом узле function формировать запрос, который пойдет на вход узлу SQL источник
let number = 1;
msg.payload = {};
msg.payload.query = 'select ' + number + ' as nm';
return msg;
Код потока SQL source 2
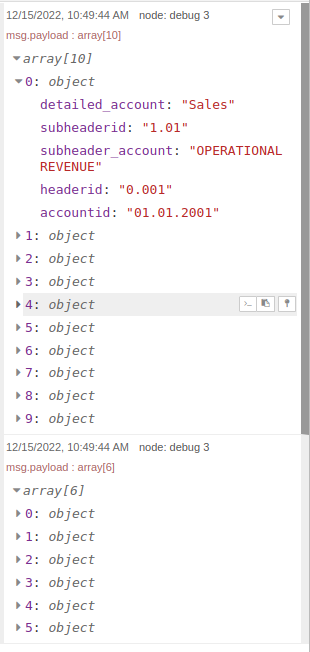
Так же, при многострочном запросе есть возможность прописать количество сообщений, объединенных в массив, например, в данном случае 10 сообщений (строк запроса) будут объединены в один массив, остальные 6 строк - в другой массив:
SQL источник с массивамиПри этом, если мы попробуем в запрос прописать функцию которая ничего не возвращает, например:
CREATE PROCEDURE custom.create_table_foo()
AS $$
CREATE TABLE custom.foo ( id int )
$$ LANGUAGE sql;
При запросе данной процедуры (CALL custom.create_table_foo();) получим следующий ответ:
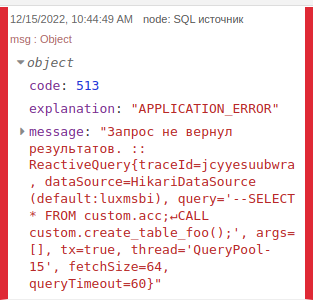
SQL источник при запросе без возвратаПри этом, при запуске того же запроса с помощью узла Выполнить произвольный запрос на сервере:

Выполнить произвольный запрос на сервереПолучим следующий ответ:
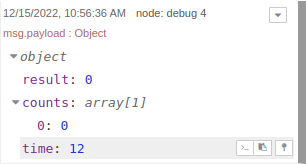
Выполнить произвольный запрос на сервереА при запросе SELECT 1 получим ошибку:
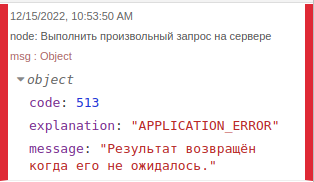
Выполнить произвольный запрос на сервере запроса 1Код потока SQL source 3
Перенос данных (sql/xlsx/csv/dbf/qvd/avro/parquet)
Узел Перенос данных дает возможность загрузить в базу данных различные данные из файлов форматов:
- Excel (xls/xlsx);
- csv;
- dbf;
- qvd;
- avro;
- parquet.
В данном примере рассмотрим возможность прогрузки файла в формате .xslx.
Для этого создадим простейший поток.

Сам узел имеет множество различных параметров, каждый из которых разберём отдельно:
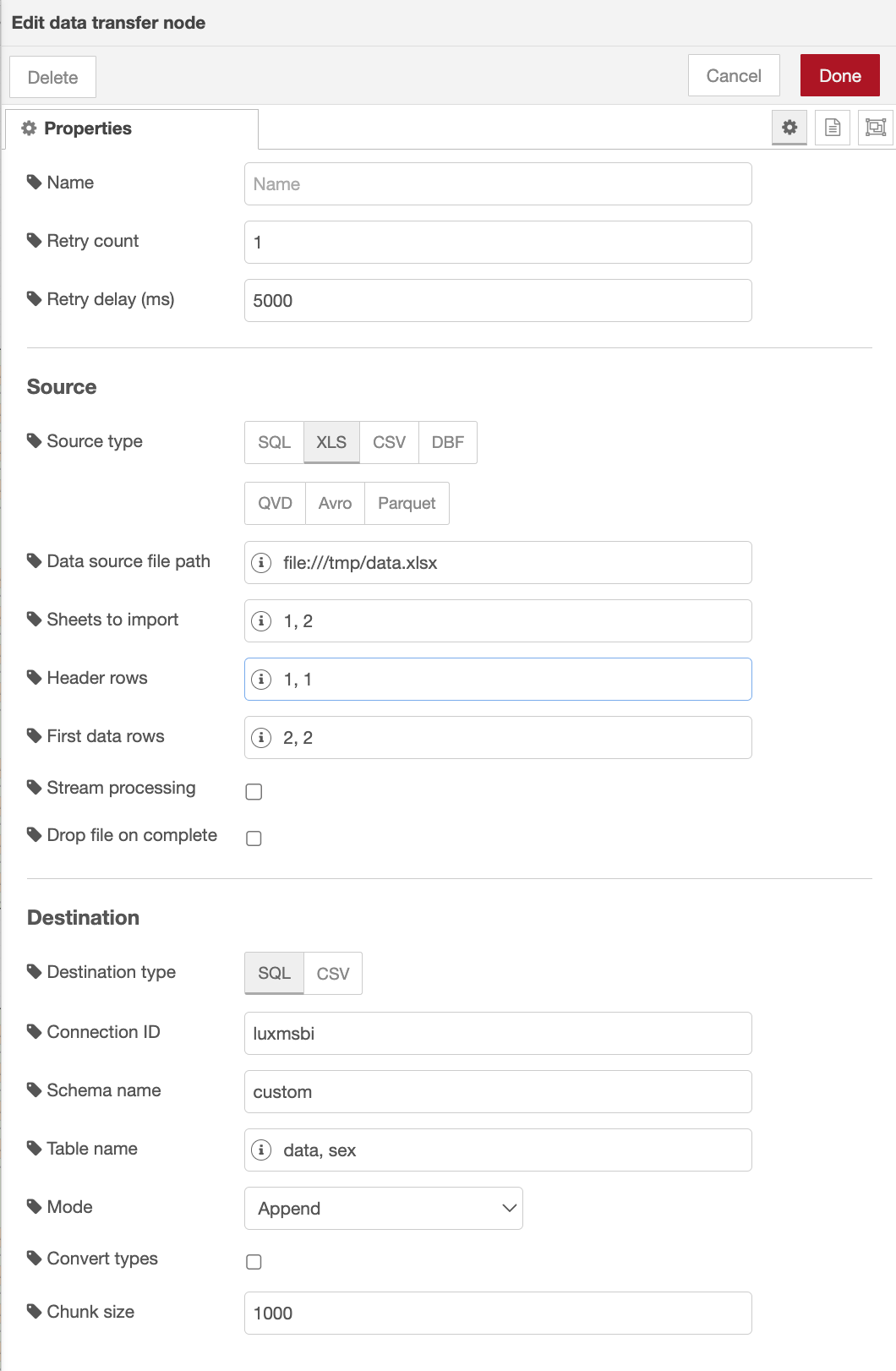
- Параметры из потока дают возможность принимать конфигурацию данного узла из данных потока (например заданных ранее узлом function);
- Тип данных - выбор типа загружаемого файла (excel/csv/dbf/qvd/avro/parquet);
- Идентификатор получателя - наименование id источника данных, стандартный источник -
luxmsbi(можно посмотреть в административной панели во вкладкеИсточник данных); - Путь к файлу - абсолютный путь к файлу, расположенному на том же сервере, что и база данных;
- Номер строки заголовка - номер строки заголовка данных, по стандарту - 1 строка, можно выбрать любую (если заголовка нет, можно оставить поле пустым);
- Номер первой строки с данными - аналогично строке заголовка, можно выбрать с какой строки будут начинаться данные (в случае с 1 строкой с заголовком -> 2 строка будет с данными);
- Список номеров страниц - можно выбрать только необходимые листы из файла excel, для прогрузки;
- Имя схемы - наименование схемы в базе данных, в которую требуется прогрузить данные;
- Имя таблицы - можно задать имя таблицы, в которую прогрузятся данные из файла, иначе наименование таблицы будет соответствовать наименованию листа excel с транслитерацией (
лист = list), (для многолистовой прогрузки рекомендуется оставить пустым, в таком случае все листы прогрузятся в таблицы с наименованиями, соответствующими наименованиям листов файла); - Mode - тип загрузки данных:
- Drop - удаление таблицы с соответствующим наименованием и замена на новосозданную;
- Append - добавление данных без какого-либо удаления;
- Truncate - отчистка таблицы с соответствующим наименованием и загрузка данных в неё.
- Преобразовывать типы - можно преобразовать типы данных в подходящие по логике, то есть чтобы числовые значения были в таблице в столбце с типом данных
int, дата в форматеdateи т.д. В связи с множеством различных вариаций форматов, после прогрузки желательно скорректировать, при необходимости, форматы. Иначе можно прогрузить данные в формате ‘text’, то есть как есть, без каких-либо изменений; - Удалить файл по завершении - удалить исходный файл после прогрузки для освобождения места на диске.
В результате, после выполнения узла получаем следующие данные:
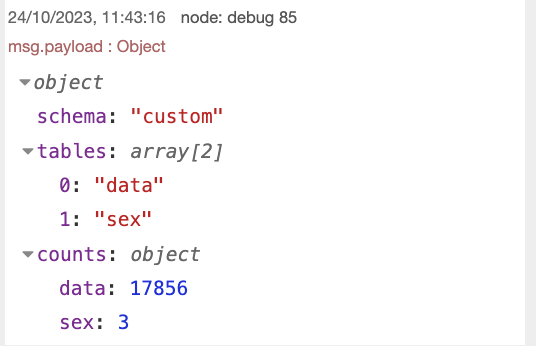
Перенос данных- Наименование схемы, в которую были прогружены данные;
- Наименования таблиц, в которые были прогружены данные;
- Количество строк, которые были загружены в базу.
Код потока Importing files
http in / http response
С помощью узлов http in и http response, а так же любого html в узле шаблон можно создать веб-страницу по пути .../databoring/....
Рассмотрим простейший пример:

В узле http in (Load) можно указать следующие параметры:
Метод запроса:
- GET
- POST
- PUT
- DELETE
- PATCH
URL страницы, который будет расположен по пути
.../databoring/;Имя узла.
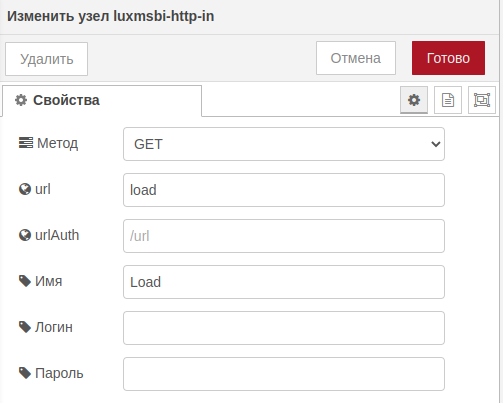
http inВ узел шаблон пропишем html следующего содержания:
<!DOCTYPE html>
<html>
<head>
<title>Заголовок</title>
</head>
<body>
Какой-то текст
</body>
</html>
В результате получаем страницу следующего содержания:
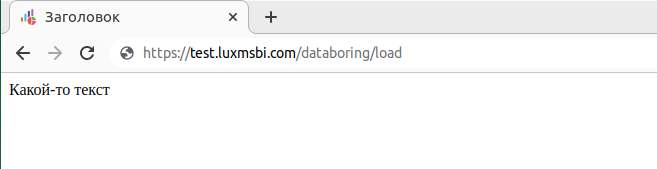
Так же можно собирать более сложные страницы, содержащие css, javascript, логику, переходы на другие страницы и т.д.
Например рассмотрим следующий поток:

В узел шаблон (css) пропишем css страницы:
div {
height: 200px;
position: absolute;
width: 480px;
height: 200px;
top: 40%;
left: 40%;
/* background dash */
background: #FFFFFF;
box-shadow: 0px 10px 20px rgba(79, 79, 155, 0.05), 0px 2px 6px rgba(79, 79, 155, 0.05), 0px 0px 1px rgba(79, 79, 155, 0.05);
border-radius: 8px;
}
p {
font-family: Roboto, Arial;
text-align: center;
font-size: large;
}
text-info{
position: absolute;
width: 438px;
height: 225px;
top: 5%;
left: 5%;
}
body{
background-color: #F2F2F8;
}
/* CSS */
.button-y {
background-color: #5FB138;
border-radius: 8px;
border-style: none;
box-sizing: border-box;
color: #FFFFFF;
cursor: pointer;
display: inline-block;
font-family: Roboto, Arial;
font-size: 16px;
font-weight: 600;
width: 216px;
height: 48px;
line-height: 20px;
list-style: none;
margin: 0;
outline: none;
padding: 14px 16px;
position: relative;
text-align: center;
text-decoration: none;
transition: color 100ms;
vertical-align: baseline;
user-select: none;
position: absolute;
top: 40%;
left: 25%;
-webkit-user-select: none;
touch-action: manipulation;
}
.button-y:hover {
opacity: 0.7;
},
.button-y:focus {
background-color: #F082AC;
}
copyright {
display:block;
margin-top: 100px;
text-align: center;
font-family: Helvetica, Arial, sans-serif;
font-size: 12px;
font-weight: bold;
text-transform: uppercase;
position: absolute;
top: 80%;
left: 44%;
}
copyright a{
text-decoration: none;
color: #EE4E44;
}
А в узел шаблон пропишем html следующего содержания:
<!DOCTYPE html>
<html>
<head>
<title>Вгрузка завершена</title>
<style>
{{{css}}}
</style>
</head>
<body>
<div>
<text-info>
<p>Данные вгружены</p> <hr>
<a href="/databoring/start" class="button-y">В начало</a>
</text-info>
</div>
<copyright>
<a class="fusion-no-lightbox" href="https://luxmsbi.com/" target="_self">Luxms BI</a>
</a>
</copyright>
</body>
</html>
В результате получим страницу следующего вида:
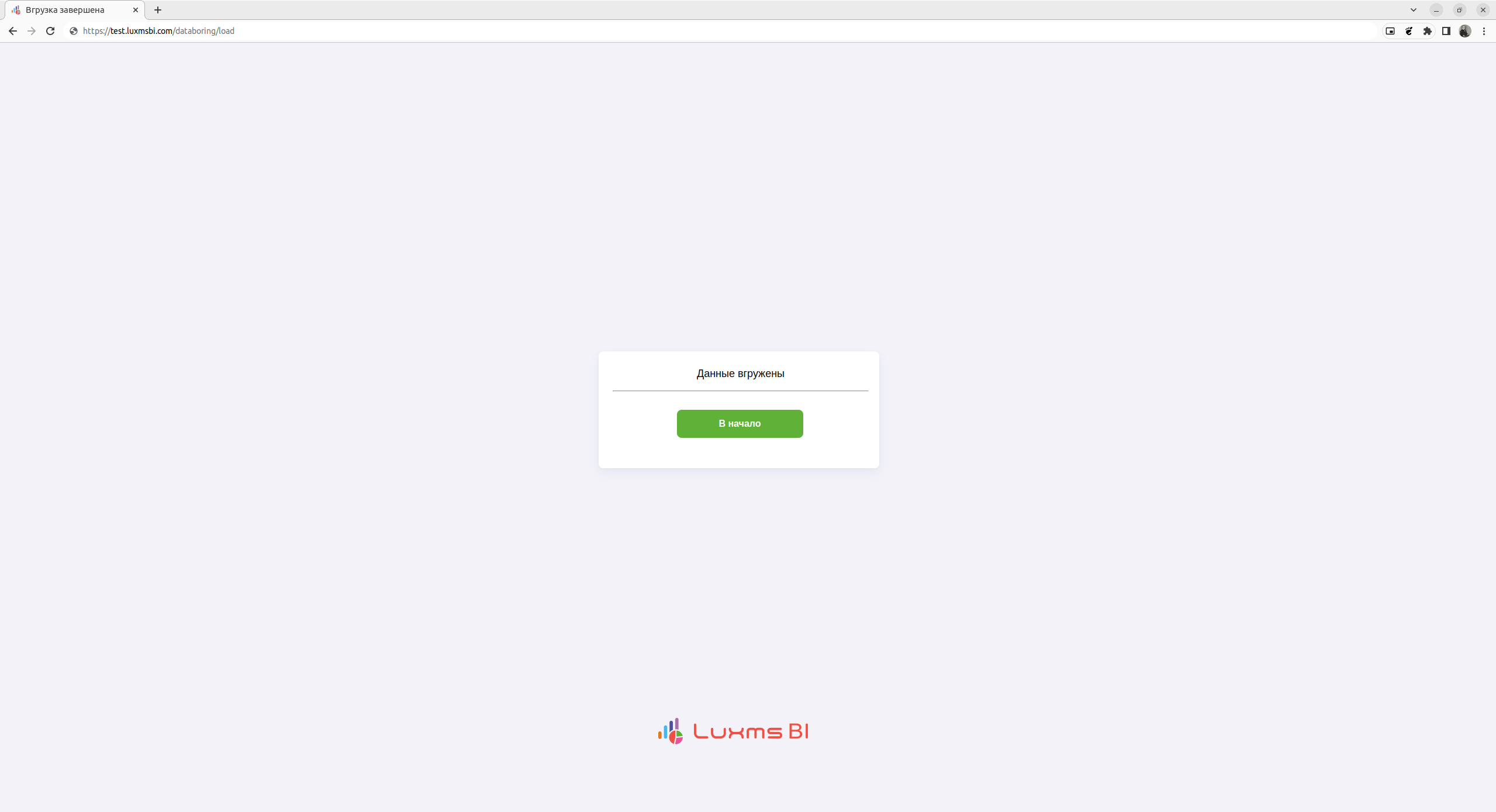
Данная страница так же выводит статический текст, но при этом ведет на страницу start при нажатии на кнопку.
Более сложные потоки могут содержать большее количество переходов, динамически изменяемый текст (например полученный ранее из базы с помощью узла SQL источник) и т.д.
Код потока http in / http response с использованием css
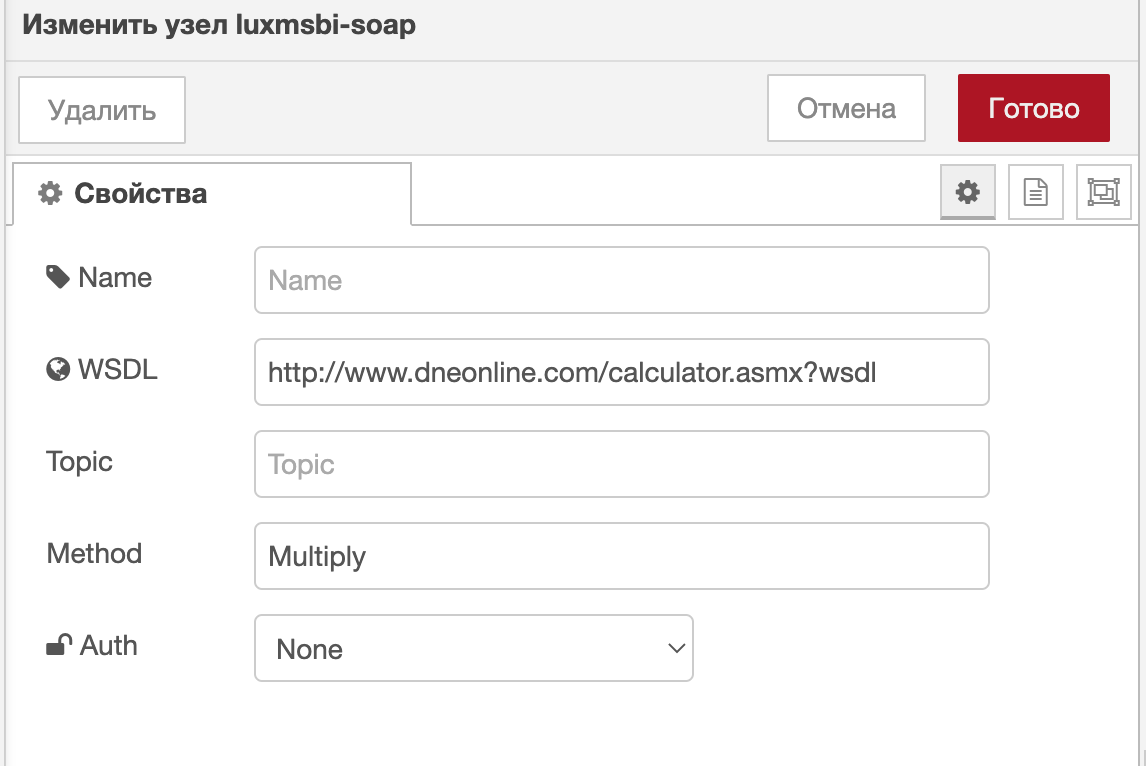
Запуск службы SOAP
Пример потока, который вызывает метод Multiply службы SOAP wsdl и
возвращает результат операции. Измените значения параметров А и B в узле функция.

Код, установленный в узле функция, и поданный на вход узлу SOAP
var newmsg={
options:{},
headers:{},
payload:{"intA":2, "intB":56}
};
return newmsg;
Поля, которые были установлены в свойствах узла SOAP
Результат выполненного потока, отображенного в окне отладки
{
"options": {},
"headers": {},
"payload": {
"MultiplyResult": 112
},
"_msgid": "7c10c7c011faa72c"
}
Код потока Launching the SOAP service
Ожидание исполнения узлов
Пример потока с использованием узла luxmsbi-wait, который ждет выполнения узлов SQL источник и собирает результат их выполнения в массив.

Данный узел принимает уникальные сообщения, инициализированными узлами меткой времени.
Результат выполненного потока, отображенного в окне отладки
[
{
"id": "1d55ec772780a987",
"payload": {
"num": 2
}
},
{
"id": "39fb76d0f77058ff",
"payload": {
"num": 1
}
}
]
Код потока Waiting for node execution
Использование библиотеки exceljs
Данная библиотека позволяет производить следующие операции:
Чтение/запись файлов формата
Excel,Работа с данными в ячейках,
Работа со стилем.
Основы: импорт, типы данных
Вызов библиотеки происходит следующим образом:
const Excel = global.get('EXCEL');
Основным объектом является т.н. Workbook, в котором производится дальнейшая работа.
const workbook = new Excel.Workbook();
После создания объекта и можно производить основные манипуляции c файлами в формате Excel. C помощью данной библиотеки можно не только считывать готовые Excel файлы, но и создавать свои с помощью различных методов. Рассмотрим случай, когда нам необходимо вытащить все данные из готового Excel.
Для загрузки экселя в Workbook необходимо выполнить команду:
await workbook.xlsx.readFile("PATH_TO_FILE");
PATH_TO_FILE - путь к файлу, хранящемуся на сервере Luxms Data Boring.
Теперь в нашем Workbook загружены данные и можно приступать к их считыванию.
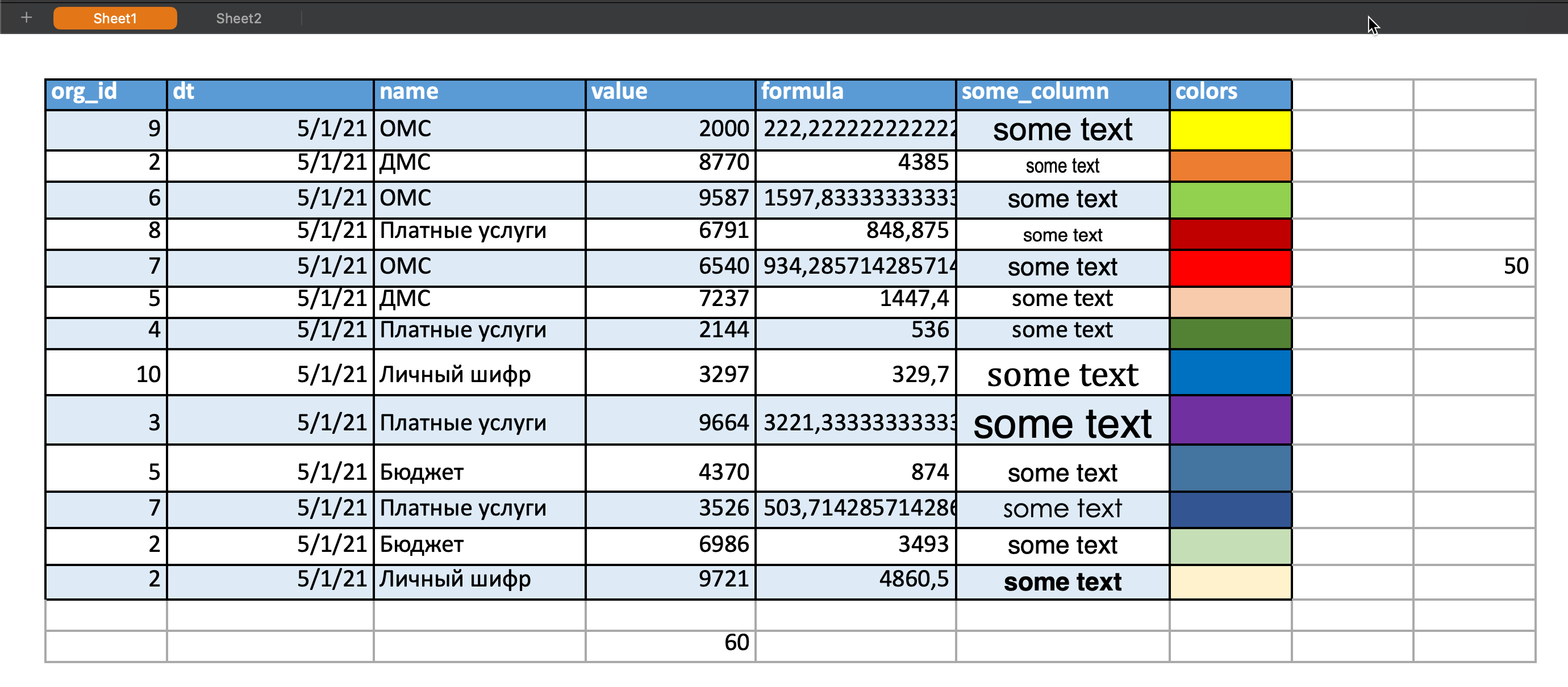
Excel файл представляет из себя:
- 2 листа - Sheet, Sheet2
- Различные типы колонок (числа, дата, формула, ячейки с измененными стилями написания и цвета)
- Значения, выходящие за пределы таблицы.
Чтение всех данных из листов
Данные можно считывать разными способами. Все зависит от задачи, которая стоит перед вами.
Например, если необходимо просто считать данные с листа, то можно воспользоваться следующим кодом:
const e = global.get('EXCEL');
const wb = new e.Workbook();
await wb.xlsx.readFile("/tmp/exceljs_xlsx.xlsx");
let data = new Array();
wb.eachSheet(function (ws, sheetId) {
let wsData = new Array();
ws.eachRow({ includeEmpty: true }, function (row, rowNumber){
let rowData = new Array();
row.eachCell({ includeEmpty : true }, function (cell, colNumber) {
let cellData = cell.value;
rowData.push(cellData);
});
wsData.push(rowData);
});
data.push(wsData);
});
msg.payload = {};
msg.payload.data = data;
return msg;
Результат выполнения кода следующий:
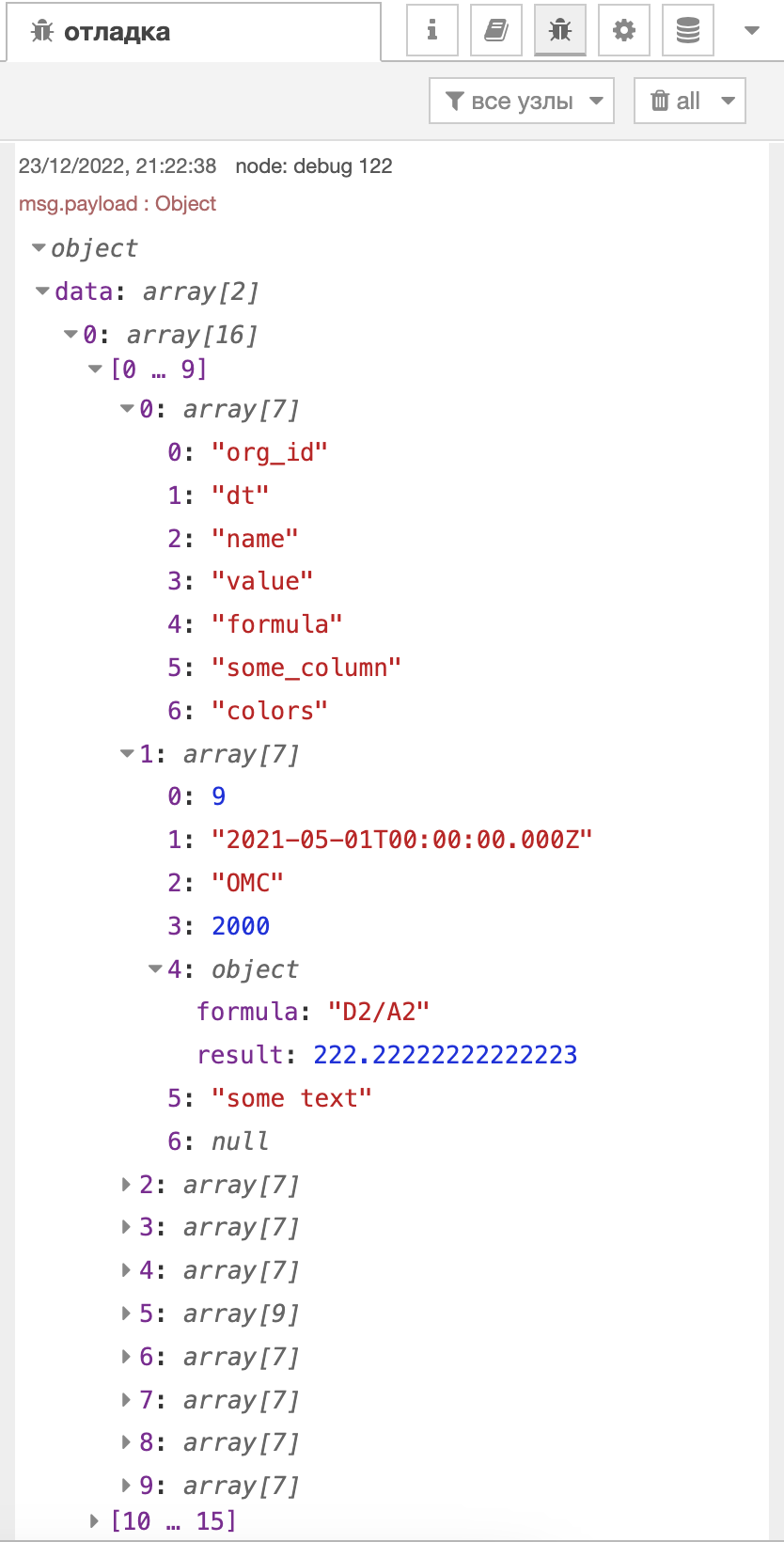
Таким образом, у нас получается структура, которая повторяет наполнение Excel файла. В дальнейшем можно производить различные манипуляции над этими данными.
Отметим некоторые моменты:
Параметр
{includeEmpty : true [false] }отвечает за то, возвращать ли в результат пустые листы/строки/ячейки,Парсится весь документ как вширь, так и вглубь. Поэтому если выбрать параметр
{includeEmpty : true }, то конечный массив получится тем больше, чем дальше у вас какое-нибудь одиночное мисс-клик значение. Рекомендаций по выбору параметра нет, это зависит от чистоты входных данных.Параметр
{includeEmpty : true }вместо пустых значений вставляет значениеnullФормулы понимаются как
object, у которого есть свойства:1)
result- результат выполнения формулы, 2)sharedFormula- указатель ячейки, откуда бралась формула, 3)formula- формула, по которой происходило вычисление, 4)ref- ссылка на ячейки, на которые распространяется формула, 5)shareType- тип шейринга.
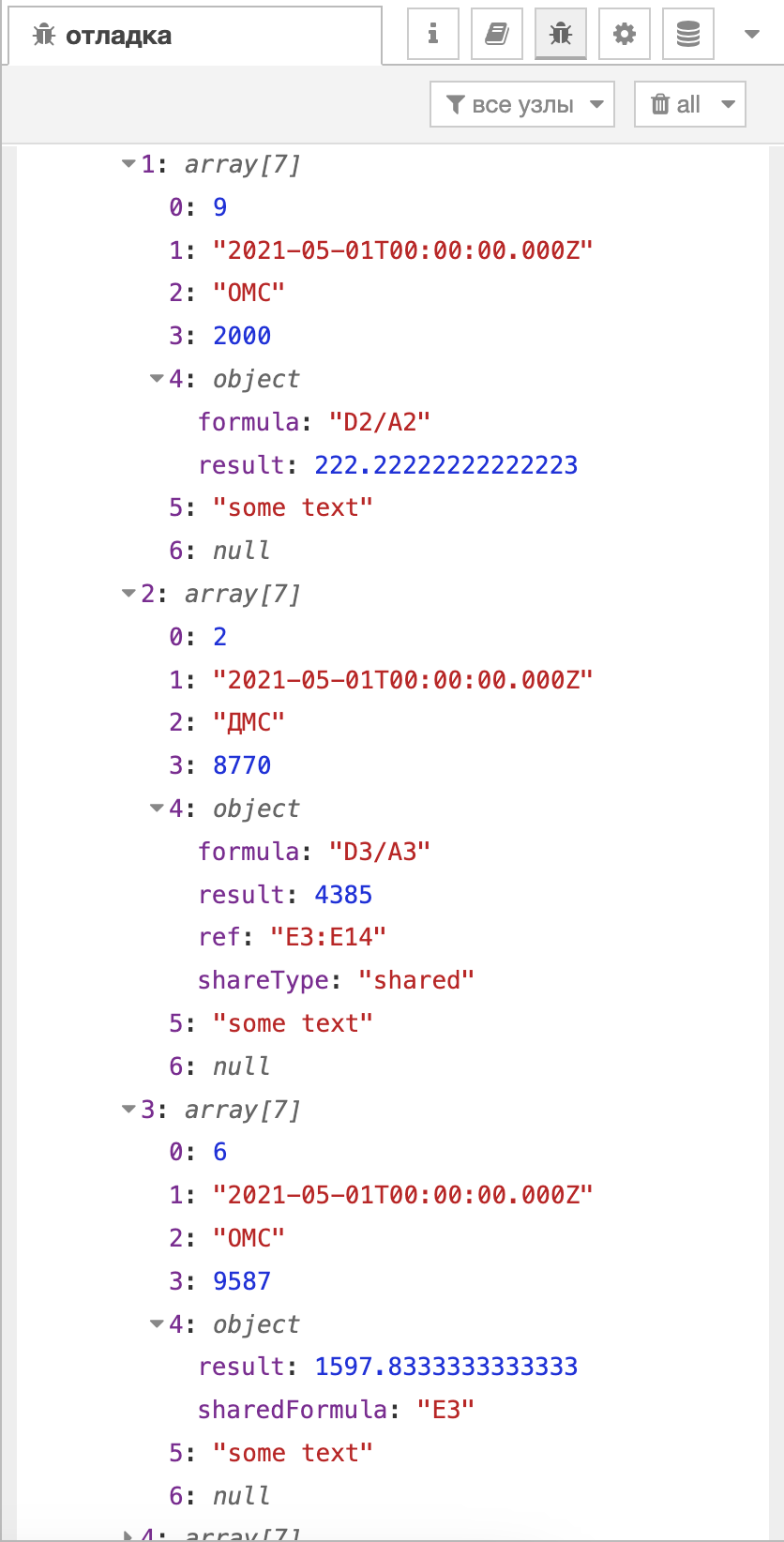
В данном примере мы видим только свойства объектов, где стоит формула. Добавление следующего кода позволит нам доставать именно значения формул:
let cellData = cell.value;
if (typeof cellData==='object' && colNumber===5) {
cellData = cell.value.result;
};
rowData.push(cellData)
Но с данной конструкцией стоит быть внимательным, потому что бывают случаи, когда формула расшарена, но нет никакого результата выполнения (например, когда вызов происходит из пустой ячейки), следовательно не может произойти и вызова к свойству result. Данную ситуацию можно эффективно обходить с помощью конструкции try...catch.
Также стоит отметить, что дата (столбец dt ) тоже имеет тип object, поэтому в данном случае лучше указать конкретный столбец, где находится формула, чтобы не получать TypeError.
Нумерация как для столбцов, так и для строк начинается с 1.
Типы данных в ячейках
Помимо вызова к ячейке метода value можно обращаться методом type, который определяет какой тип значения стоит в конкретной ячейке.

Ниже представлен перевод численного значения
| Null | 0 |
|---|---|
| Merge | 1 |
| Number | 2 |
| String | 3 |
| Date | 5 |
| Hyperlink | 5 |
| Formula | 6 |
| SharedString | 7 |
| RichText | 8 |
| Boolean | 9 |
| Error | 10 |
Стиль ячеек
У ячеек, помимо значения и типа, также существует стиль, метод style помогает нам работать с ним.
Заменив в коде выше метод value на style получим следующее:

С помощью этого метода можно смотреть такие данные, как:
font- информация о шрифте,border- информация о границах,fill- информация о цвете наполнения ячейки,alignment- информация о расположении текста в ячейке (напр. тип выравнивания).
Вывод
С помощью библиотеки exceljs можно работать со всеми мета-данными, которые определяют конечный вид Excel файла, такими как значения в ячейках, их тип данных и стиль, в котором исполнена конкретная ячейка.
В зависимости от конкретной задачи это бывает очень полезно, например, когда дата документа подсвечена жёлтым цветом и мы легко сможем определить именно эту конкретную ячейку и потом каким-либо образом использовать эту информацию в дальнейшем.
В конечном итоге, результат парсинга будет определяться лишь набором эвристических правил, по которым будет осуществлен поиск и важно понимать какую именно информацию можно получать с помощью данной библиотеки.
Базовые методы работы
Автоматический поиск заголовка
Для примера будем использовать следующий Excel файл со следующей структурой:
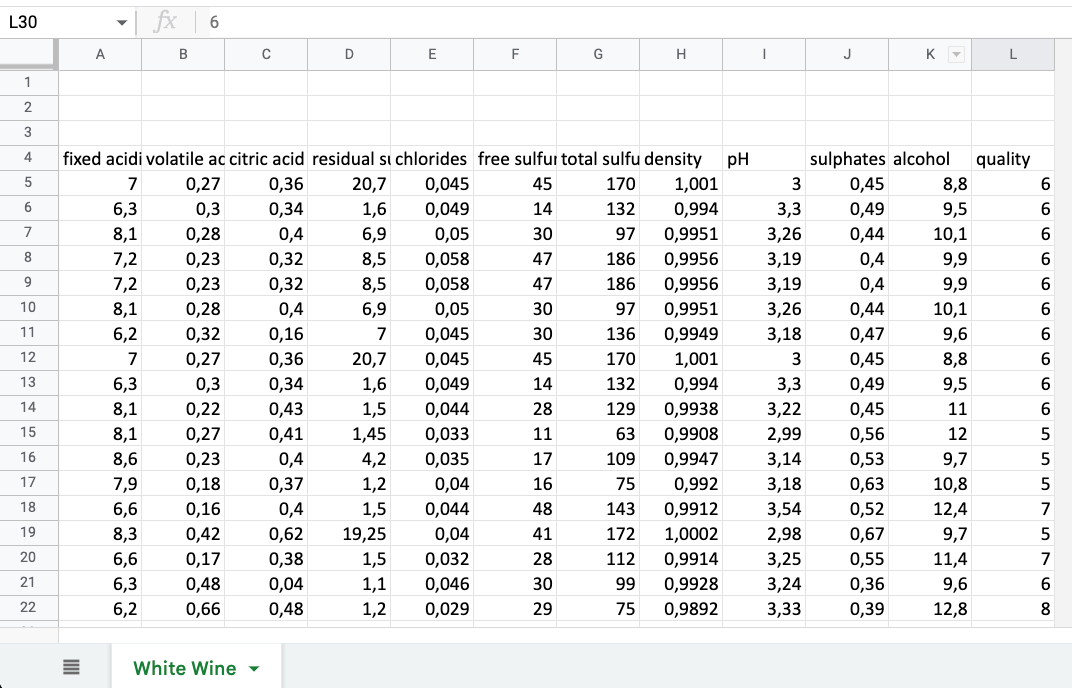
Рассмотрим тривиальную задачу - необходимо загрузить Excel файл в БД с использованием Luxms Data Boring. Следующий поток обработки имеет вид:

Для загрузки подобным образом помимо стандартных параметров необходимо указать:
Номер строки, на которой находятся заголовки,
Номер строки, с которой начинаются данные.
Перед вставкой нужно предварительно проанализировать Excel файл. Для динамической подстановки данных параметров можно воспользоваться библиотекой exceljs. Для этого используется следующий алгоритм - строка, содержащая заголовки, содержит все значения типа string.
Добавив в поток обработки узел function, в котором прописан алгоритм, имеем следующий вид:

У узла function с наименованием findHeader вставлен следующий код:
const Excel = global.get('EXCEL');
const workbook = new Excel.Workbook();
await workbook.xlsx.readFile("/tmp/wine_data.xlsx");
const worksheet = workbook.getWorksheet("White Wine");
const isString = (currentValue) => typeof currentValue == "string";
let findHeader = true;
let headerName;
let headerRow;
let dataRow;
worksheet.eachRow({ includeEmpty: true }, function(row, rowNumber) {
let readRow = new Array();
row.eachCell({ includeEmpty: true }, function(cell, colNumber) {
readRow.push(cell.value);
});
if (findHeader) {
if (readRow.every(isString) && readRow.length !== 0) {
headerName = readRow;
headerRow = rowNumber;
dataRow = rowNumber + 1;
findHeader = false;
};
};
});
msg.payload = {};
msg.headerRow = headerRow;
msg.firstDataRow = dataRow;
msg.headerName = headerName;
return msg;
Алгоритм, реализованный в узле function:
Проходим по файлу
Excelи записываем каждое значение в строкуreadRow.Если установлена опция
findHeader, входим в блокif:1) Если все значения в строке
readRowтипаstringи строка не пуста:1) Записываем заголовки, находящиеся в строке readRow, в переменную `headerName`.
2) Записываем номер текущей строки `rowNumber` в переменную `headerRow`.
3) Записываем в переменную `dataRow` номер строки `rowNumber + 1`.
4) Сбрасываем флаг `findHeader` так как заголовки уже найдены.
Результат работы алгоритма:

По выводу видно, что алгоритм работает корректно, так как удалось найти заголовки и вывести их имена, а также загрузить Excel файл в БД.
Частичное чтение информации из файла
Не только чтение, но и запись в файлы с помощью библиотеки exceljs также возможна. Например, можно записывать части исходного excel файла в отдельный csv файл. Рассмотрим пример на основе файла wine_data.xlsx.
Для решения этой задачи понадобятся следующие методы:
| rowCount | Общее количество строк в документе. Равняется номеру последней строки, в которой есть хотя бы одно значение. |
|---|---|
| actualRowCount | Общее количество непустых строк. То есть, если в середине документа строки будут пустыми, то они не будут учитываться. |
| columnCount | Общее количество столбцов в документе. |
| actualColumnCount | Общее количество столбцов в документе, в которых есть хотя бы одно значение. |
Примечание: разница между total и actual - это количество пустых строк/столбцов, которые встречаются в документе. Рассмотрим этот момент на примере, запустив следующий код:
const Excel = global.get('EXCEL');
const workbook = new Excel.Workbook();
await workbook.xlsx.readFile('/tmp/wine_data.xlsx');
const worksheet = workbook.getWorksheet('White Wine');
msg.rowCount = worksheet.rowCount
msg.actualRowCount = worksheet.actualRowCount
msg.columnCount = worksheet.columnCount
msg.actualColumnCount = worksheet.actualColumnCount
return msg;
После запуска потока обработки объект msg имеет следующее содержание:
{
"_msgid": "b4500b5b7ee142b7",
"payload": 1672122420477,
"topic": "",
"rowCount": 4902,
"actualRowCount": 4899,
"columnCount": 12,
"actualColumnCount": 12
}
Выяснено, что методы работают корректно, подсчитывая строки и столбцы. Первые 3 строки были исключены из подсчета actualRowCount.
Пусть требуется записать последние 5 столбцов первых 200 строк excel файла в отдельный csv файл. Можно воспользоваться следующим кодом:
const Excel = global.get('EXCEL');
msg.filename = '/tmp/wine_data_csv.csv';
const workbook = new Excel.Workbook();
await workbook.xlsx.readFile('/tmp/wine_data.xlsx');
const worksheet = workbook.getWorksheet('White Wine');
const newWorkbook = new Excel.Workbook();
const newWorksheet = newWorkbook.addWorksheet('wineSheet');
let startColumn = worksheet.actualColumnCount - 4;
let endColumn = worksheet.actualColumnCount;
let startRow = 5;
let endRow = 205;
for (let r=startRow, k=1; r <= endRow; r++, k++) {
var row = worksheet.getRow(r);
var newRow = await newWorksheet.getRow(k);
for (let col=startColumn; col<=endColumn; col++) {
newRow.getCell(col-startColumn+1).value = row.getCell(col).value;
};
};
await newWorkbook.csv.writeFile(msg.filename, { sheetName: 'wineSheet' });
return msg;
После выполнения этого кода и использования узла read file можно увидеть следующий вывод в окне отладки:
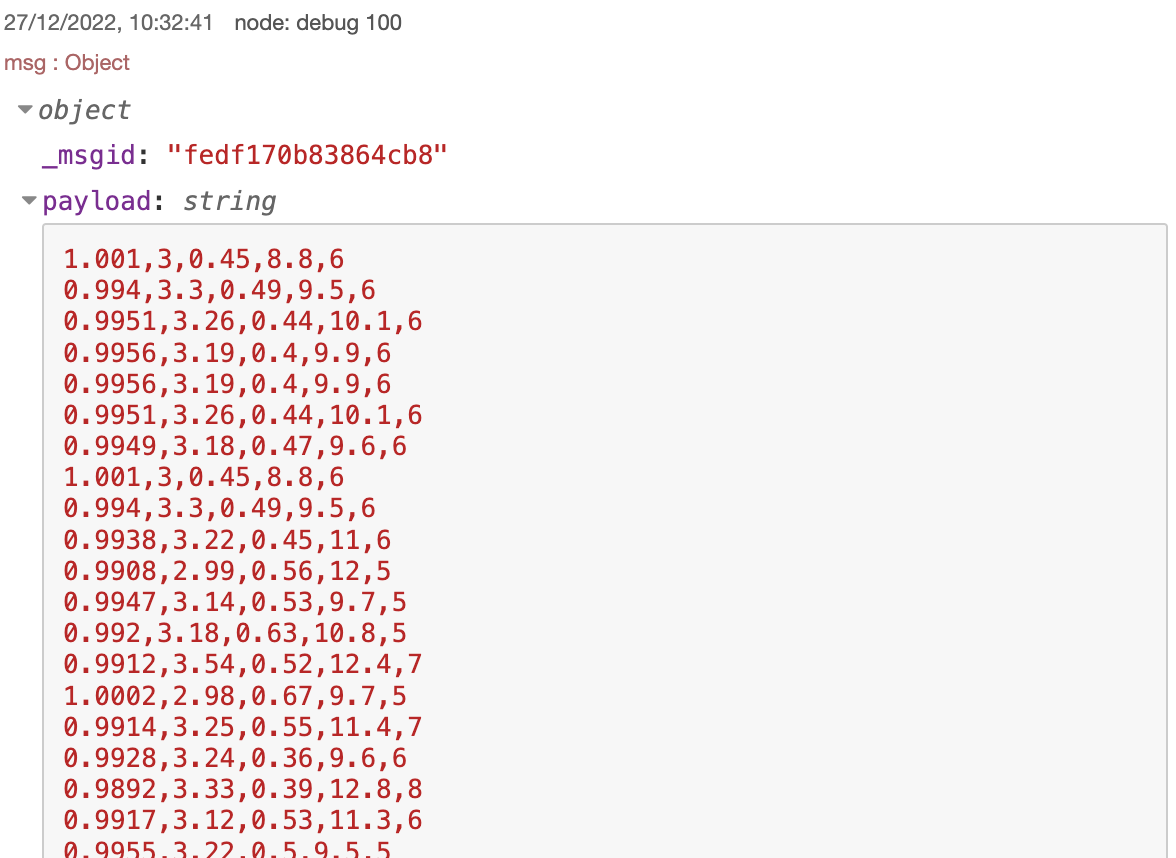
Работа алгоритма заключается в проходе по excel файлу с помощью двух циклов for. Внешний цикл отвечает за проход по строкам, внутренний отвечает за проход по столбцам.
Для записи файла следует инициализировать новый Workbook и записать в него нужную часть исходного excel файла с помощью конструкции .getCell(col).value. Затем этот новый excel файл можно преобразовать в CSV с помощью метода .csv.writeFile(msg.filename, { sheetName: 'wineSheet' });, где:
msg.filename- путь, куда мы сохраняемCSVфайл;sheetName- название листа, куда сохраняли необходимые значения.
Сохранение таблиц со сложной шапкой в БД из Excel файла
В случае, когда необходимо парсить файл и записать его сразу в БД, не всегда стандартные средства Luxms Data Boring могут помочь, например, при наличии сложной шапки таблицы. Проблема заключается в том, что невозможно точно указать, с какой строки начинаются заголовки и начинаются данные.
Чтобы решить проблему с парсингом файла со сложной шапкой и записью в БД, можно использовать средства exceljs. В качестве примера можно взять файл со следующей структурой:
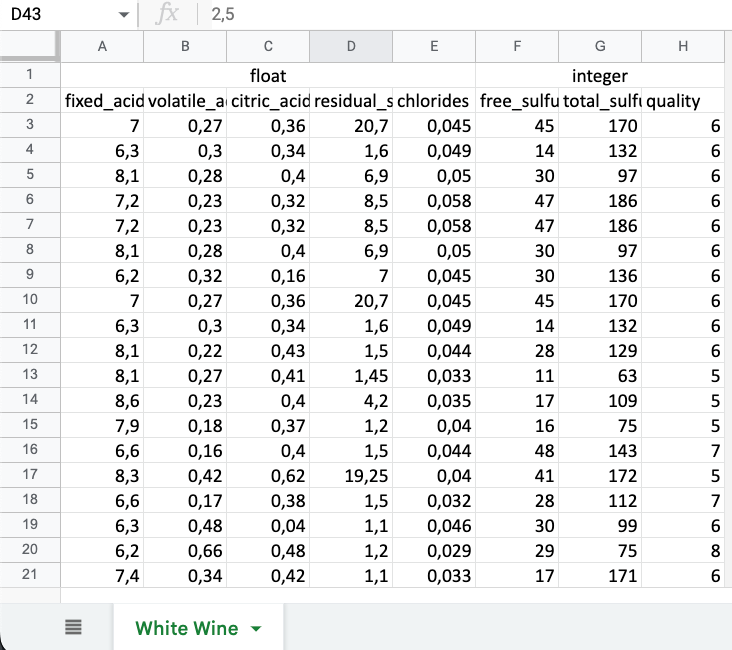
Появились новые заголовки, которые указывают на то, является ли столбец целочисленным или дробным числом. Требуется сохранить эту информацию.
Для выполнения данной задачи используется поток следующего вида:
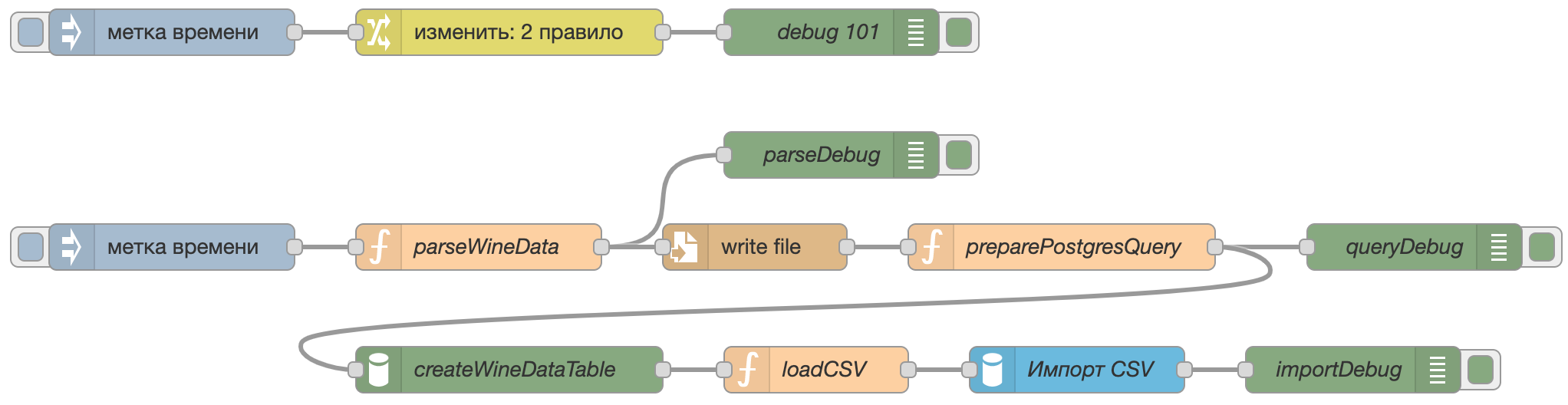
Для начала нужно задать имя таблицы и путь сохранения csv файла в узле change.
В узле function с наименованием parseWineData содержится следующий код:
const Excel = global.get('EXCEL');
const workbook = new Excel.Workbook();
await workbook.xlsx.readFile('/tmp/wine_data_head.xlsx');
const worksheet = workbook.getWorksheet('White Wine');
const isString = (currentValue) => typeof currentValue == "string";
var headerName = new Array();
var headerRow;
var wb_csv = new Array();
worksheet.eachRow({ includeEmpty: true }, function (row, rowNumber) {
let readRow = new Array();
row.eachCell({ includeEmpty: true }, function (cell, colNumber) {
let valueCell = cell.value;
readRow.push(valueCell);
});
if (readRow.every(isString)) {
headerName.push(readRow);
headerRow = rowNumber;
};
wb_csv.push(readRow);
});
// Создание csv
let wbRaw = new Array();
wb_csv.slice(headerRow).forEach(function (infoArray, index) {
var line = infoArray.map(function (elem, i) {
if (String(elem) === 'null') {
return ''
} else {
return '\"' + String(elem) + '\"'
};
}).join(",");
wbRaw.push(line);
});
let wbPrepare = wbRaw.join("\n");
// Работа с заголовками
const regex = /[^a-z]/gi;
let header = headerName[0]
for (let i = 1; i < headerName.length; i++) {
let headerPast = headerName[i - 1];
let headerNow = headerName[i];
for (let j = 0; j < headerPast.length; j++) {
if (headerPast[j] !== headerNow[j]) { header[j] = header[j] + '_' + headerNow[j]; };
};
};
let clearHeader = header.map(element => element.replace(regex, ' ').trim().replace(/\s+/g, '_').toLowerCase().substr(0, 60));
msg.payload = {};
msg.a = clearHeader;
msg.payload = wbPrepare;
msg.filename = flow.get('path');
return msg;
Данный код можно, условно, разделить на три части:
Формирование массива строк
wb_csv, который затем будет превращен вcsvфайл.Для каждой ячейки пробегается, затем складывает в строку, и строку складывает в массив. Если все значения в строке текстовые, номер строки запоминается для последующего обрезания массива.
Непосредственно создание
csv.Созданный ранее массив конкатенируется. Удобство данного способа в том, что мы сами выбираем какое значение будеть иметь статус
NULL.Работа с заголовками.
Алгоритм выполняет простую операцию с заголовками - если следующий заголовок равен предыдущему, то он пропускает. В противном случае конкатенирует строки между собой, преобразуя их в формат, который будет использоваться в запросе для создания БД в
PostgresSQL.Следует отметить, что значения в объединенной колонке читаются для каждой ячейки отдельно, что позволяет не упускать значения в конкретной ячейке.
Заголовки сохраняются в объекте
msg, чтобы в дальнейшем построить по ним таблицу в БД.
Вывод этого узла будет выглядеть следующим образом:
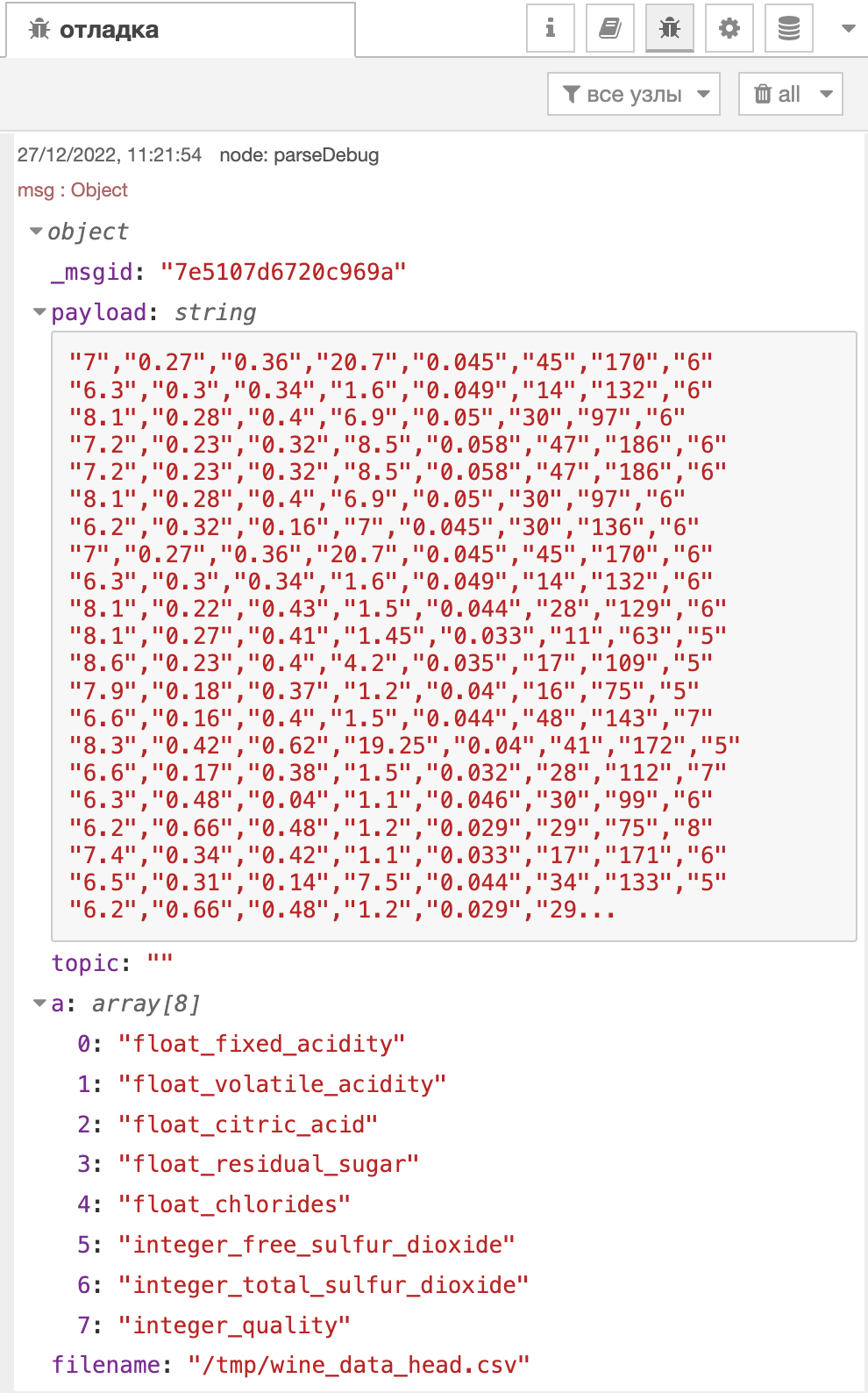
Узел write file возьмёт из потока msg.payload и msg.filename и создаст необходимый csv файл.
В узле preparePostgresQuery содержится следующий код:
msg.payload = {};
msg.a = (msg.a.join('" text NULL, \r\n"') + '" text NULL');
msg.payload.query = 'CREATE TABLE IF NOT EXISTS ' + flow.get('table') + '\n' + '(' + '\n' + '"' + msg.a + '\n' + ')' + '\;' + '\n' + 'TRUNCATE TABLE ' + flow.get('table') + '\;';
return msg;
Данный код просто строит SQL запрос в БД, который построит таблицу. Вывод этого узла будет таким:
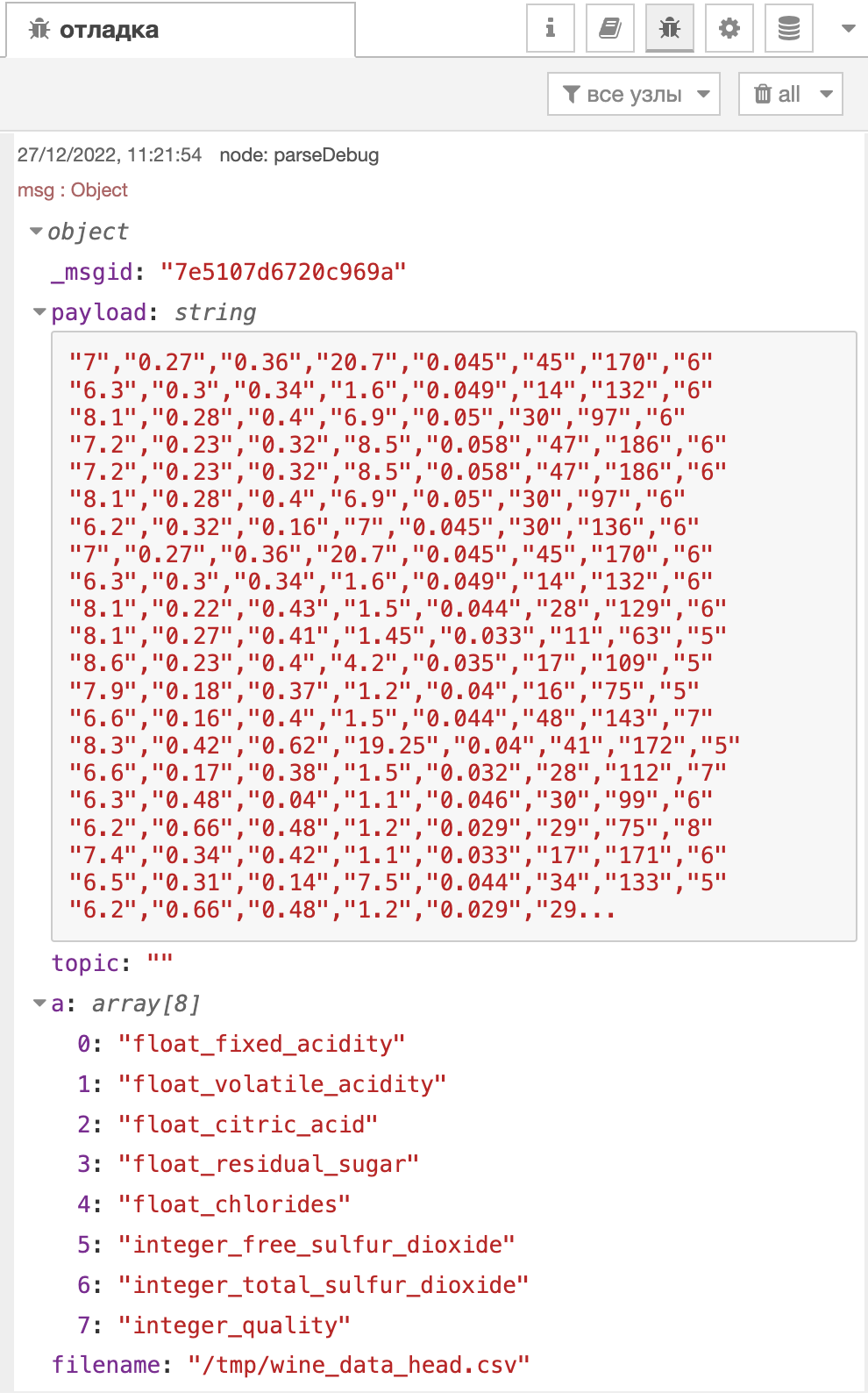
function с наименованием preparePostgresQueryВ узле createWineDataTable происходит создание таблицы из запроса, который лежит в msg.payload.query.
Узел loadCSV содержит следующий код:
msg.payload = {};
msg.payload.sink = 'file://' + flow.get('path');
msg.payload.table = flow.get('table');
return msg;
Таким образом, параметры задаются для следующего узла Импорт CSV. Это удобно, когда заранее известно, в какую таблицу и откуда нужно что-то складывать.
После загрузки данные успешно были загружены в БД.
Вывод
Библиотека exceljs может покрыть большинство задач связанных с чтением и записью файлов. Она также мощна и может быть интегрирована с хранилищем S3, что позволяет отправлять данные туда, где они реально нужны, минуя различные этапы. Возможности библиотеки не ограничиваются только работой с Excel файлами.
Чтение файлов
С помощью узла read file можно читать файлы, например можно прочитать файл в формате .csv.
В данном примере рассмотрим вариант чтения файла с несколькими строками, каждая из которых будет содержать информацию о определённом файле и его кодировку, для корректного импорта данных в базу.
Так же в поток добавим узел csv для разбиения строк под свой отдельный объект сообщения.

read file и csvСам узел имеет следующие параметры:
- Имя файла: абсолютный путь к файлу;
- Вывод:
- одна utf-8 строка;
- сообщение для каждой строчки;
- один объект буфера;
- поток буфера.
- Выбор кодировки;
- Имя узла.
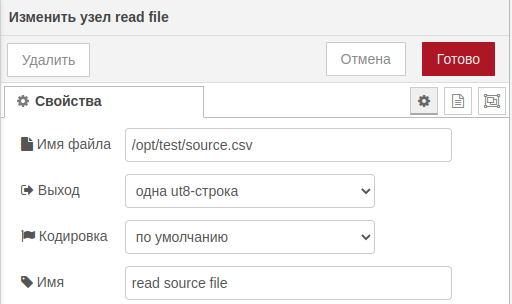
read fileПосле прочтения простейшего файла следующего вида:
buffer_table,file_name,encoding
custom.test_1,test_1.csv,utf-8
custom.test_2,test_2.csv,windows-1251
Получим следующий ответ:
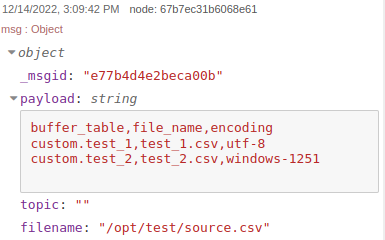
read fileРазобьем файл на отдельные объекты сообщения с помощью узла csv, где пропишем параметры нашего csv файла:
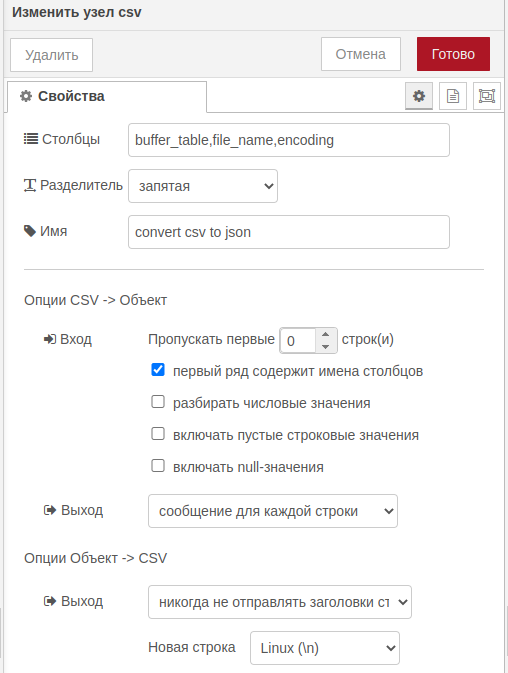
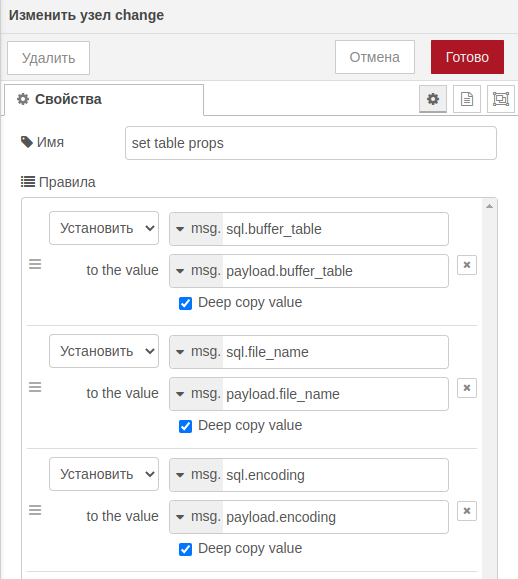
csvТак же для удобства можно переопределить объект сообщения на другой с помощью узла change:
В результате всех произведённых действий получаем следующий ответ:
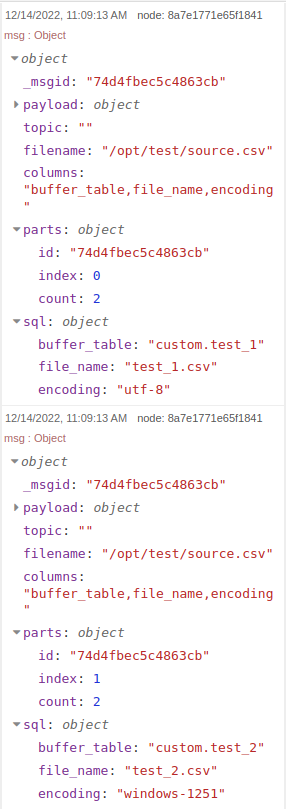
read file и csvВ результате разделения на несколько сообщений, добавляется специальный объект parts, который служит для понимания системой из скольких частей состояло исходное сообщение (на следующих этапах может понадобится для узлов по типу join)
Код потока Reading files
Экспорт запроса данных в csv
Пример потока, который сохраняет результат запроса в файл формата .csv

Код запроса, который прописан в поле узла SQL запрос в файл
SELECT t.day::date as dt, random() * 100 + 44 AS plan, random() * 100 AS fakt
FROM generate_series(timestamp '2022-05-01'
, timestamp '2022-10-30'
, interval '1 day') AS t(day)
order by t.day::date
Код потока Exporting a data requrest to csv
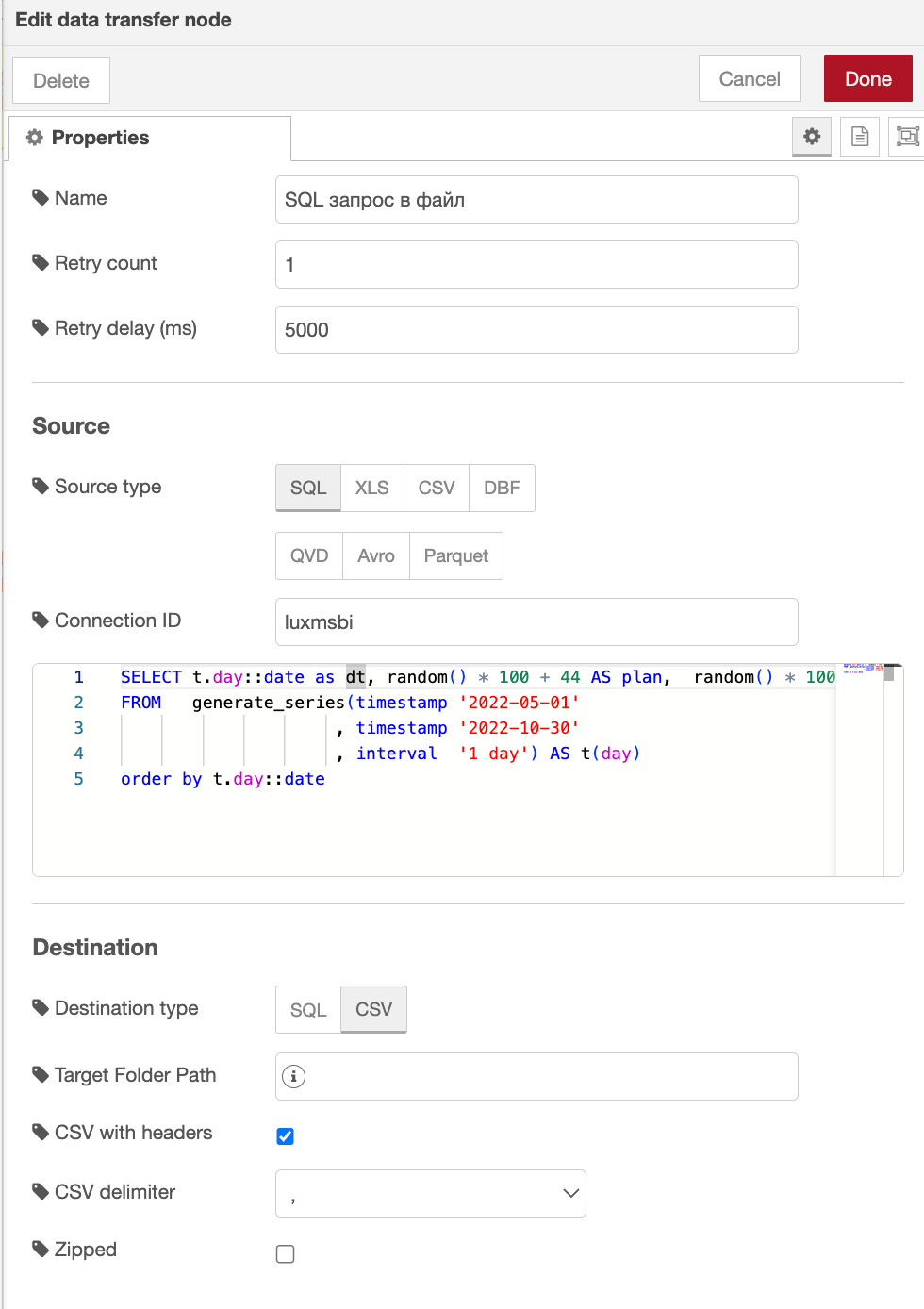
Выбранные свойства для выгрузки результата запроса из базы PostgreSQL в формате CSV в распределённое документное хранилище работающее по протоколу NATS.
Работа потока приводит к следующему результату.
Исполнение unix-команд
С помощью узла exec можно запускать любые sh скрипты. При этом, в комбинации с узлом function можно создать свой sh скрипт с запуском любых bash запросов.
В данном примере используем function для запуска скрипта python.
Для использования скриптов python, сам python должен быть развёрнут на сервере со своим витруальным окружением и со всеми установленными необходимыми библиотеками.

function (file)
В данном узле мы прописываем запросы, для запуска нашего скрипта, как делали бы это в терминале bash.
- Переходим в папку со скриптом
- Активируем виртуальное окружение
- Запускаем скрипт python
Код функции:
#!/bin/bash
cd /opt/test
source env/bin/activate
python some_script.py
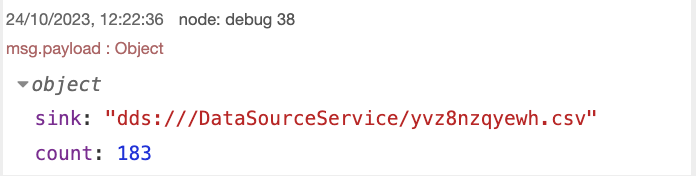
write file (save to file)
Записываем этот запрос в sh файл.
В Имя файла прописываем абсолютный путь для файла, который хотим создать.
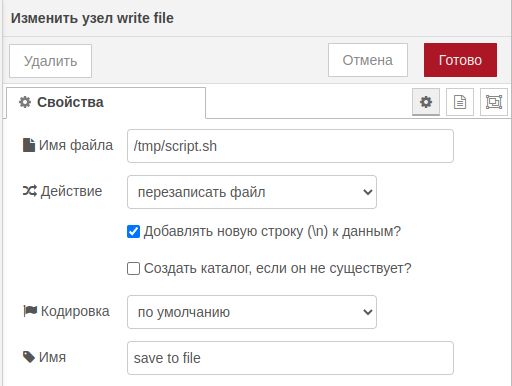
exec (make script file executable)
Меняем права на созданный файл sh (добавляем возможность исполняемости).
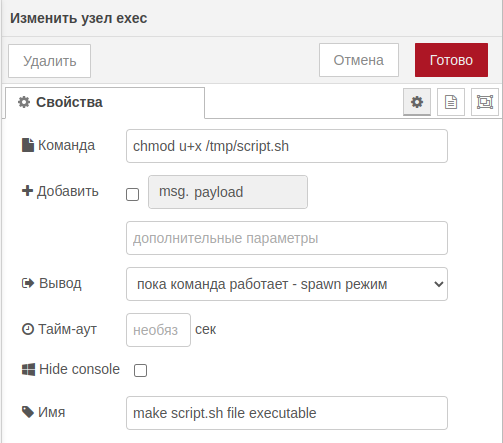
exec (execute script)
Выполняем sh.
Вывод результатов
Exec поддерживает вывод различных типов возвратов функций:
- Стандартный вывод - stdout;
- Стандартный вывод ошибок - stderr;
- Код возврата - вывод 1/0.
Если скрипт python настроен под вывод таких типов, их можно будет получать через разные выводы exec. На основании этих выводов можно будет управлять продолжением исполнения потока.
Код потока Execution of unix commands
Циклические потоки
Пример потока, который позволяет создавать циклы на основе узла loop из палитры Luxms Data Boring группы функция.
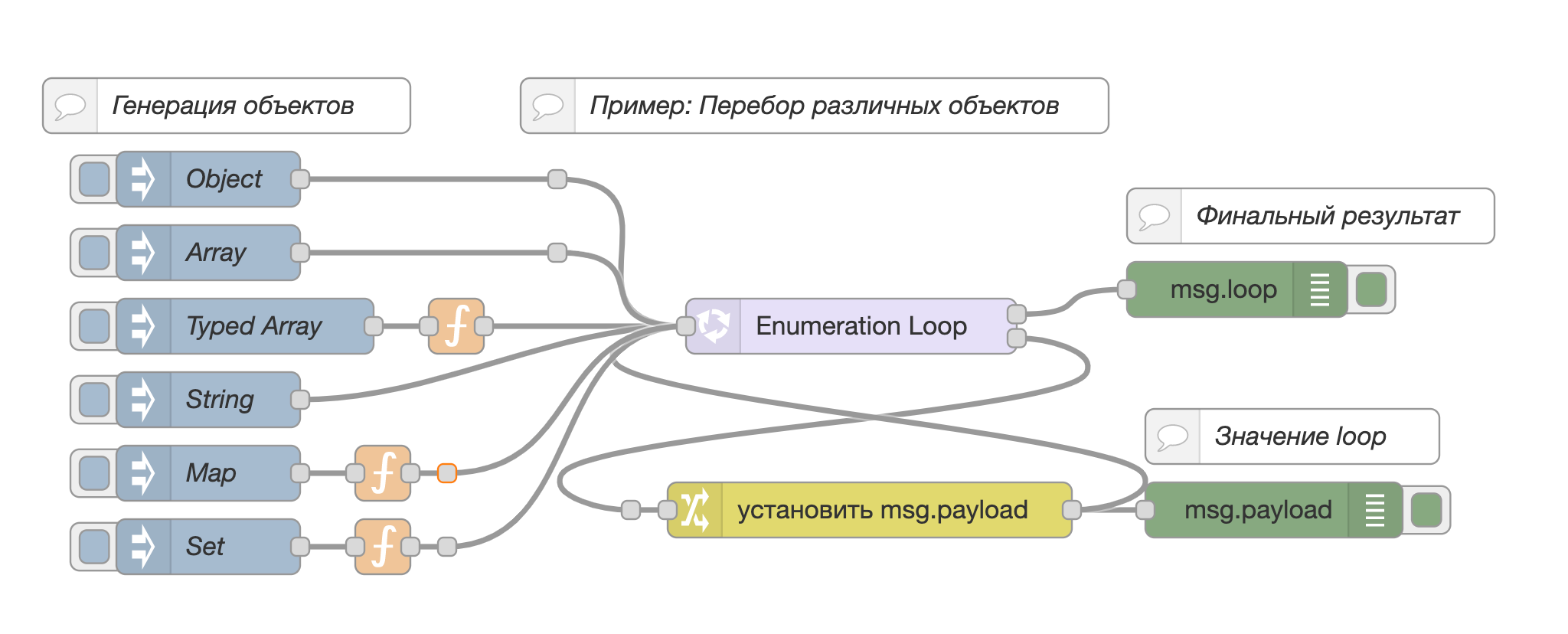
В узле метка времени в свойстве msg.payload устанавливается значение {"first":"Hello World","second":8,"third":true}, которое подается на вход узлу loop.
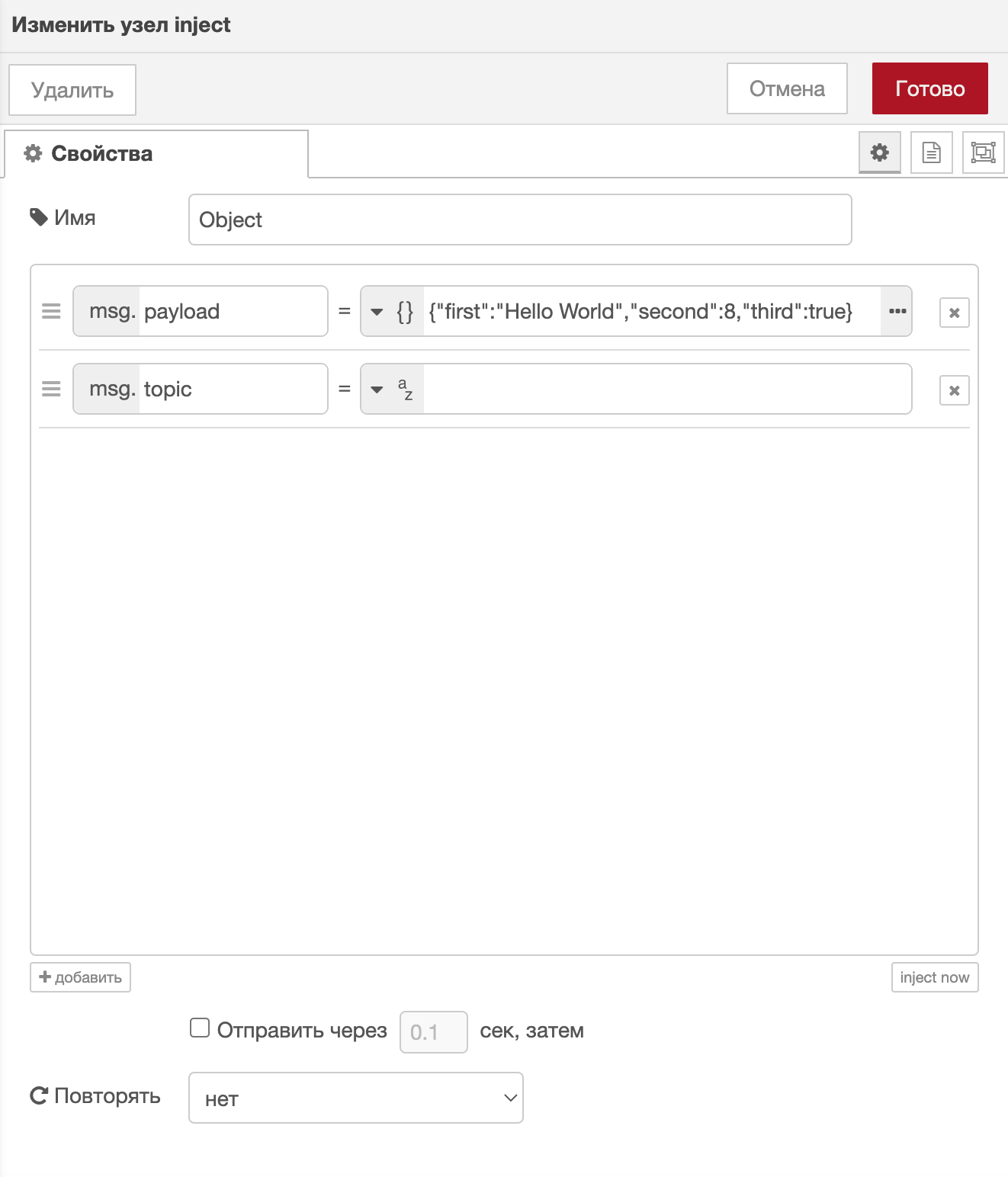
В свойствах узла loop устанавливаются параметры обработки объекта, который пришел на вход. В данном случае свойство было определено в msg.payload.
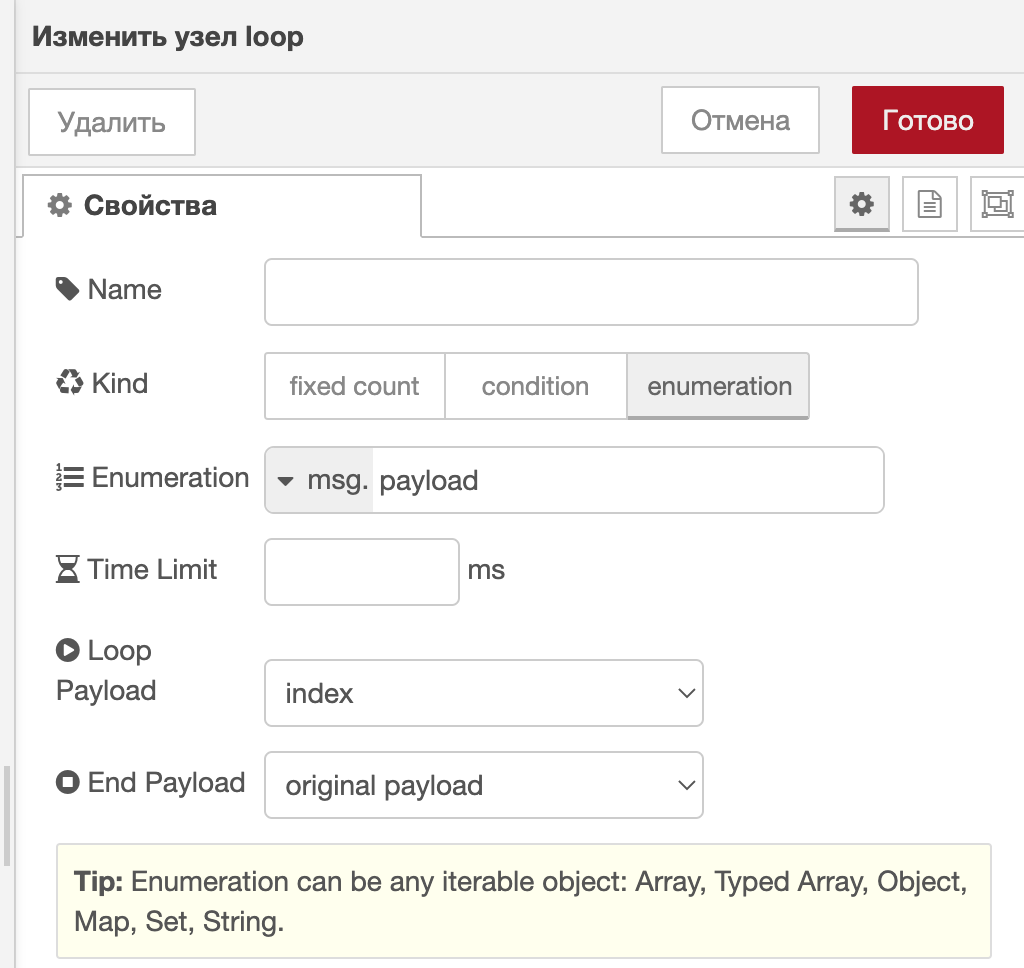
Результат выполненного потока, отображённого в окне отладки
loopКод потока Cyclic flows
Динамическая загрузка Excel файлов
Пример потока, который динамически инициализирует загрузку .xlsx файлов, появившихся в папке /tmp, используя узел watch. Библиотека exceljs позволяет опеределить два параметра: Номер строки заголовка и Номер первой строки с данными, которые подаются на вход узлу Перенос данных.
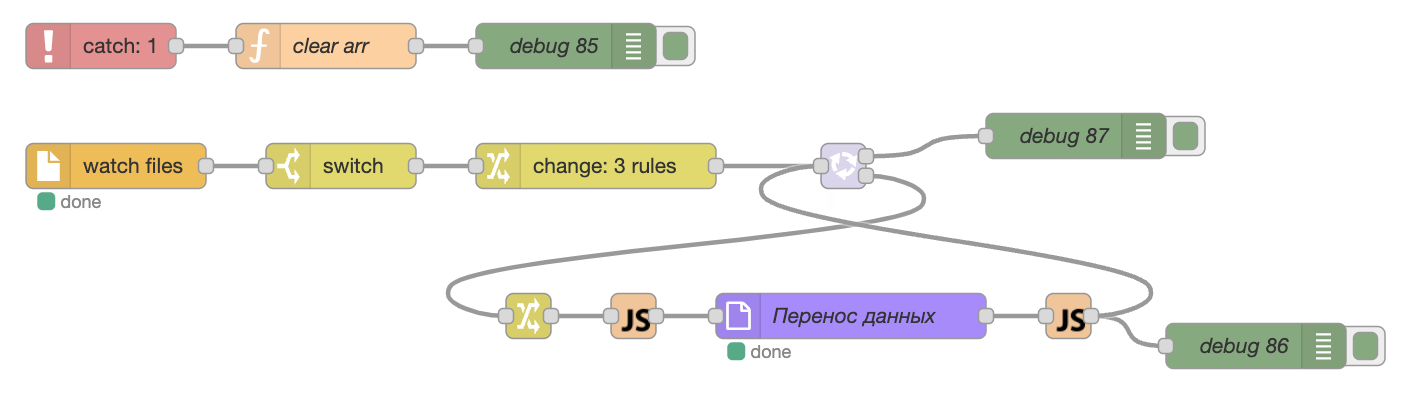
Узел Перенос данных принимает на вход параметры, которые были определены ранее в узле change. Поля в данном примере не заполняются.
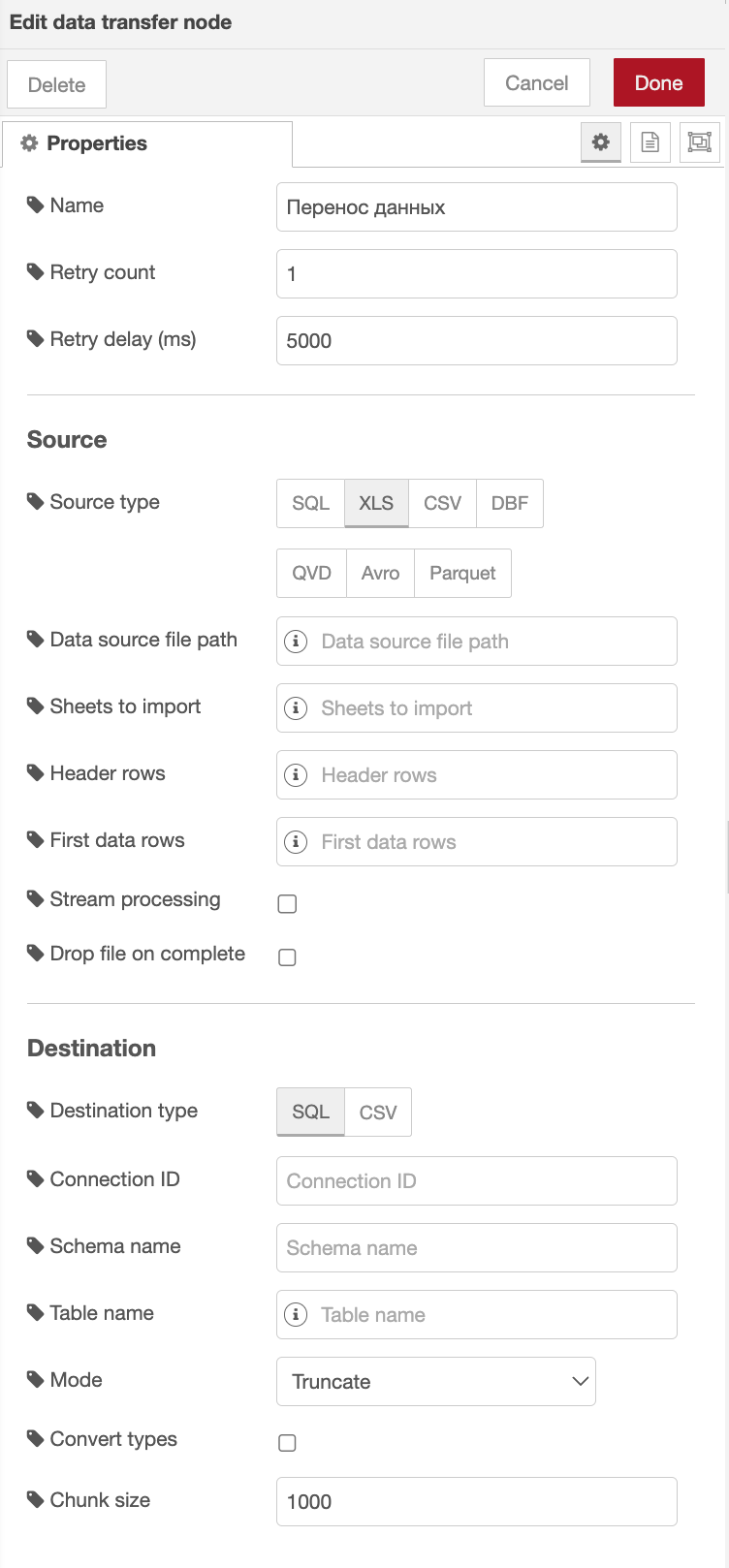
Входные параметры, установленные в узле change
Код потока Dynamic loading of Excel files
Циклическая проверка данных с помощью использования http
Входящие данные для данного примера: в начало данного потока приходит наименование датасета для поиска запроса соответствующей функции по этому наименованию.
Для работы данного потока необходима подготовленная функция в базе.
Алгоритм работы функции: на вход функции приходит код ошибки (где 0 это старт), при получении определённого кода будет производиться определённая проверка.
Проверка, которая завершилась с ошибкой, возвращает код ошибки и описание ошибки -> их мы покажем на веб интерфейсе.
На веб интерфейсе будет 2 варианта, при возникновении ошибки: ознакомиться с ошибкой и игнорировать её (продолжить) и остановить загрузку.
При варианте Продолжить мы возвращаемся в начало потока и запускаем функцию, но уже не сначала, а с кода ошибки, которую проигнорировали.
Каждый узел будет описан отдельно.

Первичная проверка запуска фунцкии
- http in
Наименование пути по http, на данном этапе нам уже необходимо получить номер датасета в данный объект (например с помощью глобальных или потоковых переменных). Или же, если нет необходимости в динамическом изменении скрипта для проверки, можно сразу указать его.
- function №1
Функция принимает наименование датасета и внедряет его в запрос к базе.
В данном примере у нас уже есть созданная таблица, в которой наименование датасета соответствует запросу процедуры. Соответственно мы просто забираем из базы запрос к функции проверки.
Код функции:
let ds = msg.payload.ds;
msg.payload.query = "select json_extract_path_text(config::json, 'function_check') FROM custom.etl_matrix WHERE schema_name = '" + ds + "'";
return msg;
- open json
Получаем запрос для функции проверки. Сам узел оставляем пустым, так как запрос мы прописали на предыдущем узле в msg.payload.query.
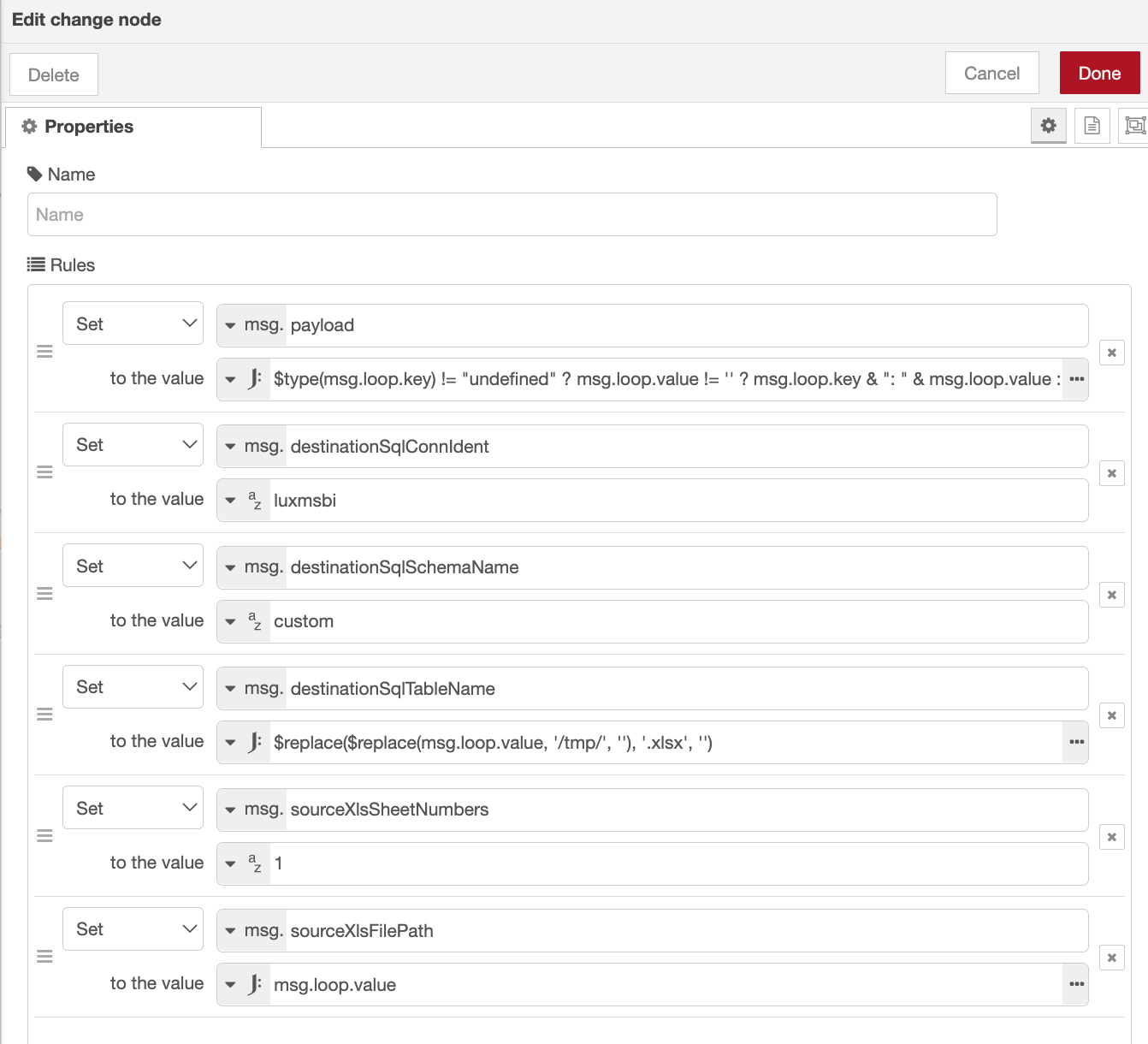
- switch 0 не 0
Создаем простейшую проверку: если функция уже запускалась, у нас будет прописан определенный ключ возврата в потоковых переменных, если нет - запускаем процедуру с ключом старта.
- function если код возврата существует
Запускаем процедуру проверки с определённым ключом (с соответствующего этапа).
Код функции:
let err = flow.get("err");
let func = msg.payload.json_extract_path_text;
msg.payload.query = "SELECT " + func + "(" + err + ")";
return msg;
- function если код возврата не существует
Запускаем процедуру с начальным ключом (0).
Код функции:
let func = msg.payload.json_extract_path_text;
msg.payload.query = "SELECT " + func + "(0)";
return msg;
Проверка кода возврата из функции
- function №4
Заносим ключ возврата в потоковые переменные.
Код функции:
let err_tmp = msg.payload.check_new_data.f1;
flow.set("err", err_tmp);
return msg;
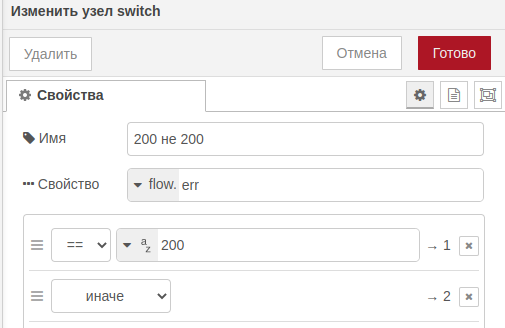
- swith 200 не 200
Если ключ 200 (ОК) - возвращаем страницу с окончанием проверок. Иначе возвращаем страницу с ошибкой и описанием.
- function если код 200
Если пришло 200 - очищаем потоковую переменную, чтобы при следующем запуске начать сначала.
Код функции:
flow.set("err", undefined);
return msg;
- template для кода 200
Страница с успешным окончанием проверок. Выводит сообщение об успешном окончании проверок.
- template для кода не 200
Страница с вариантами игнорирования проверки и продолжения проверок (возврат в начало к http in) или остановки прогрузки (две разных кнопки).
Код потока Cyclic data validation using http
Мониторинг выполнения потоков при помощи KeyDB как брокера сообщений
Концепт:
В данном решении существует три части:
1) глобальный поток, который можно поместить в один любой поток - эта часть, отвечающая за рассылку сообщений в случае зависания или долгого выполнения потока. Сюда же входит часть с глобальными параметрами, которую необходимо единоразово запустить;
2) локальный поток, к которому необходимо подключить в начало и в конец отслеживаемого потока, эта часть, сопровождающая начало и конец отслеживаемого потока. Он должен располагаться вместе с отслеживаемым потоком;
3) сам отслеживаемый поток
Идея заключается в том, что потоку в момент его запуска присваивается счётчик=время жизни (TTL) в redis/keyDB с информацией об этом потоке. Далее канал отслеживающий все действия, в том числе время жизни потока, даёт сигнал об истечении, а дальше этот сигнал используется для объявлении об этом в сообщении переменной msg.msg.
При этом в данном случае, время жизни берётся на основании истории успешного выполнения потоков, на основании этой таблицы строится представление, которое откидывает 25 и 75 персентили, работая с адекватными значниями без выбросов. А далее считается СКО - дисперсия. Существует функция, которая на выход получает имя потока и на сколько сигм=дисперсий надо отступить, чтобы захватить время исполнения.
Для работы данного потока необходимо настроенное подключение к myself_lamel (в данном примере, это бд postgres).
Развернуть таблицу с историей выполнения потоков, если нет замены - public.upload_log_sdc, представление - public.mat_stat_upload_log_sdc и функцию - public.get_all_sigma_from_flow(TEXT, double precision). Это развёртывается при помощи нод в импортируемых json-ах. Так же подключение к keyDb. Не забыть ввести HOST стенда, где производится опробация решения для ноды с http запросом.
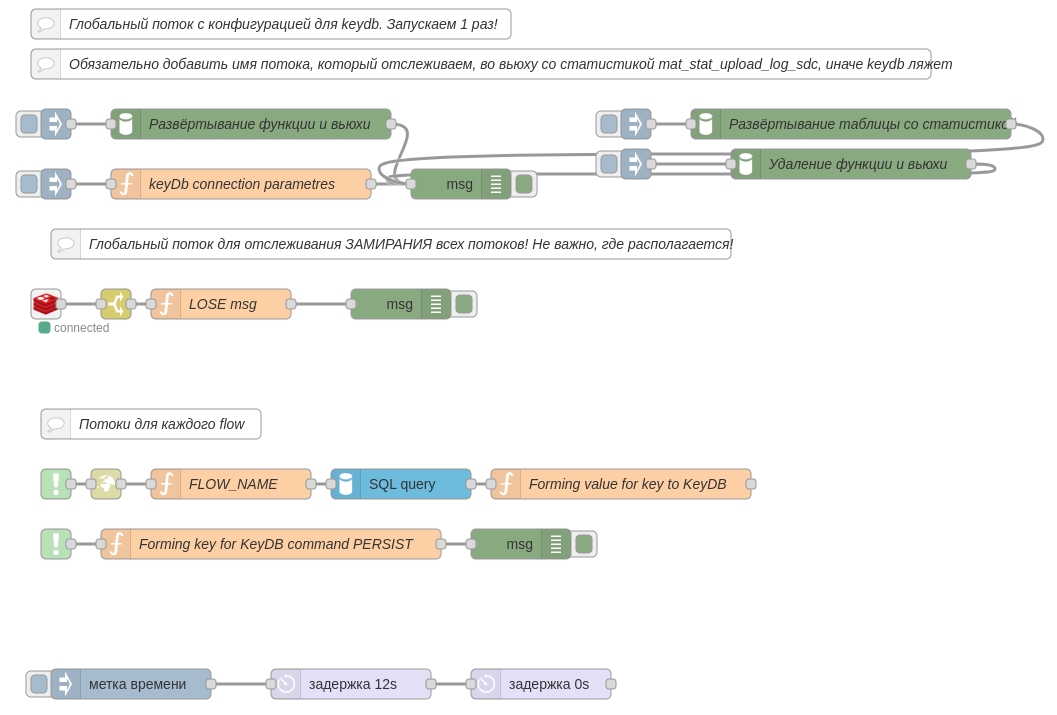
Глобальная часть
- Развёртывание таблицы со статистикой
Код функции:
DROP table if exists public.upload_log_sdc;
CREATE TABLE public.upload_log_sdc (
start_time timestamp NULL,
raw_log text NULL,
job_result text NULL,
pipeline_success text NULL,
end_time timestamp NULL,
pipe_name text NULL
);
INSERT INTO public.upload_log_sdc
(start_time, raw_log, job_result, pipeline_success, end_time, pipe_name)
VALUES('2021-07-21 18:45:00.001', NULL, NULL, 'true', '2021-07-21 23:45:05.212', 'cron_008_MUST_RUN_BUFFER');
INSERT INTO public.upload_log_sdc
(start_time, raw_log, job_result, pipeline_success, end_time, pipe_name)
VALUES('2021-07-21 20:15:00.001', NULL, NULL, 'true', '2021-07-22 01:15:05.254', 'cron_008_MUST_RUN_BUFFER');
INSERT INTO public.upload_log_sdc
(start_time, raw_log, job_result, pipeline_success, end_time, pipe_name)
VALUES('2021-07-22 04:45:00.002', NULL, NULL, 'true', '2021-07-22 09:45:05.266', 'cron_008_MUST_RUN_BUFFER');
- Удаление функции и вьюхи
Код функции:
--вью для вычисления статистики времени выполнения потоков
DROP VIEW IF exists public.mat_stat_upload_log_sdc;
--Функция, которая будет возвращать границы одной-двух-трёх сигм при получении наименования потока
DROP FUNCTION if EXISTS public.get_all_sigma_from_flow;
- Развёртывание функции и вьюхи
Код функции:
--вью для вычисления статистики времени выполнения потоков
CREATE OR REPLACE VIEW public.mat_stat_upload_log_sdc AS
WITH diff AS (
SELECT pipe_name,
EXTRACT(EPOCH FROM end_time) - EXTRACT(EPOCH FROM start_time) diff
FROM public.upload_log_sdc uls
WHERE pipeline_success = 'true'
)
,
percentile_value AS (
SELECT pipe_name,
percentile_disc(0.25) WITHIN GROUP (ORDER BY diff) perc_25,
percentile_disc(0.75) WITHIN GROUP (ORDER BY diff) perc_75
FROM diff
GROUP BY pipe_name
)
SELECT DISTINCT pipe_name, floor(avg(diff) OVER (PARTITION BY diff.pipe_name))::int avg_v,
ceil(sqrt(var_pop(diff) OVER (PARTITION BY diff.pipe_name)))::int sigma
FROM diff
LEFT JOIN percentile_value USING (pipe_name)
WHERE diff BETWEEN perc_25 AND perc_75
UNION
SELECT 'Мониторинг потоков', 8, 1
UNION
SELECT 'Lamel', 8, 1
;
COMMENT ON VIEW public.mat_stat_upload_log_sdc IS 'Представление с расчётами для каждого потока среднего значения выполнения потока с учётом выбросов, а также областей: одна-две-три сигма от этого среднего';
--Функция, которая будет возвращать границы одной-двух-трёх сигм при получении наименования потока
CREATE OR REPLACE FUNCTION public.get_all_sigma_from_flow(flow_name TEXT, multiplier double precision)
RETURNS TABLE (sigma int)
AS $$
BEGIN
IF flow_name IN (
SELECT pipe_name
FROM public.mat_stat_upload_log_sdc
)
THEN
RETURN QUERY EXECUTE 'SELECT abs(avg_v+sigma*floor($1))::int
FROM public.mat_stat_upload_log_sdc
where pipe_name = $2' USING multiplier, flow_name;
ELSE
RAISE EXCEPTION 'Flow name Error : %', flow_name;
END IF;
END;
$$
LANGUAGE plpgsql;
COMMENT ON FUNCTION public.get_all_sigma_from_flow(text, double precision) IS 'Функция, которая будет возвращать значение в зависимости от множителя для сигмы и получении наименования потока';
- keyDb connection parametres
Код функции:
// Работа с keyDB
global.set('con_config_h', '127.0.0.1'); //конфиг подключения к KeyDB хост
global.set('con_config_p', 6379); //конфиг подключения к KeyDB порт
return msg;

- redis in
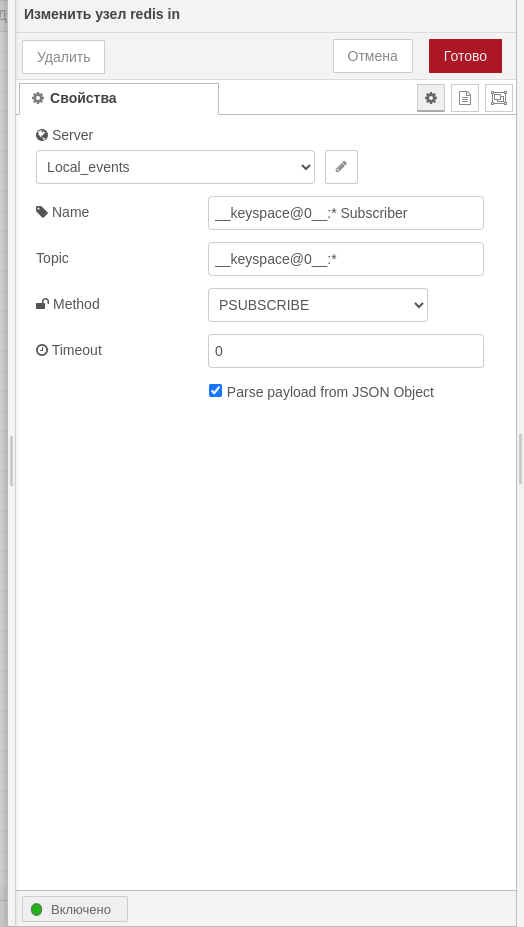
- switch
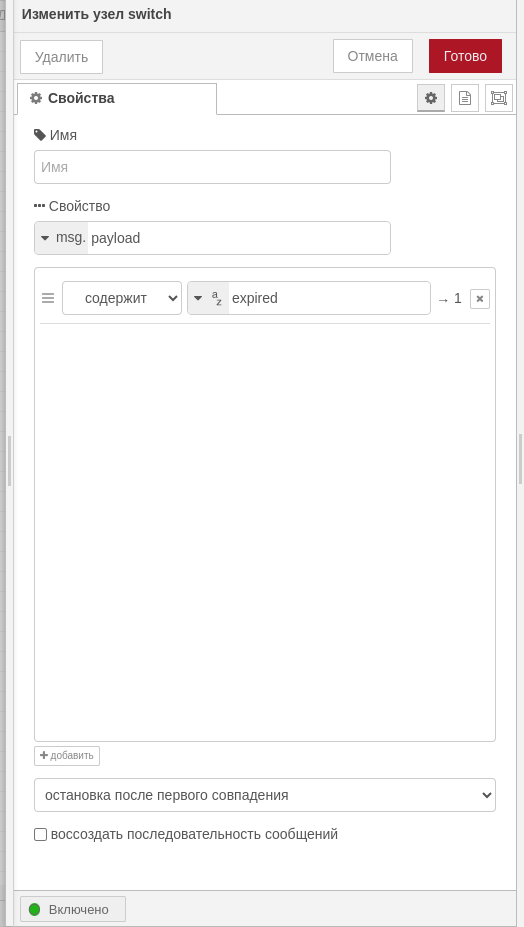
- LOSE msg
Код функции
// Работа с keyDB
let con_config_h = global.get('con_config_h'); //конфиг подключения к KeyDB хост
let con_config_p = global.get('con_config_p'); //конфиг подключения к KeyDB порт
const red = new redis(con_config_p, con_config_h); //подключение к нужному хосту и порту
let key = msg.topic.replace('__keyspace@0__:', '');
let store_key = 'store:' + key; //ключ для хранилища всех ключей и значений
let info = await red.get(store_key);
msg.msg = 'Поток долго выполняется. ИНФО: ' + info;
return msg;
Локальный поток
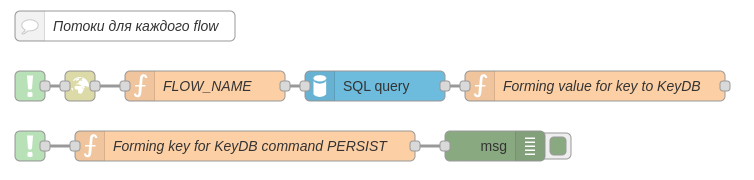
- complete
- http request
- FLOW_NAME
Код функции
msg.name = env.get('NR_FLOW_NAME'); // наименование потока
msg.user = JSON.parse(msg.payload)[0]['username']; // пользователь из датаборинга
return msg;
- SQL query
Код функции
SELECT * FROM public.get_all_sigma_from_flow('${msg.name}', 6)
- Forming value for key to KeyDB
Код функции
let time = msg.payload.sigma; // среднее время выполнения потока
msg.dt_start = new Date().toISOString();
let title = env.get('NR_FLOW_ID'); //идентификатор flow
let name = env.get('NR_FLOW_NAME'); // наименование потока
let sys_user = env.get('USER'); // пользователь системный
// формирование JSON с информацией о потоке
let info = '{' + '"flow_id":' + '"' + title + '"' + ',' + '"flow_name":' + '"' + name + '"' + ',' + '"sys_user_name":' + '"' + sys_user + '"' + ',' + '"user_name":' + '"' + msg.user + '"' + ',' + '"dt_start":' + '"' + msg.dt_start + '"' + '}';
//На вход в keyDB выполнение скрипта - команда
let run_fvalue = JSON.parse(info);
// ключ - значение для keyDB
let run_key = msg.user + title;
let run_value = '\'' + info + '\'';
flow.set('flow_key', run_key); // потоковая переменная ключ потока
// Работа с keyDB
let con_config_h = global.get('con_config_h'); //конфиг подключения к KeyDB хост
let con_config_p = global.get('con_config_p'); //конфиг подключения к KeyDB порт
let store_key = 'store:' + run_key; //ключ для хранилища всех ключей и значений
const red = new redis(con_config_p, con_config_h); //подключение к нужному хосту и порту
red.set(run_key, run_value); // устанавливаем ключ значение для текущего потока
red.set(store_key, run_value); // устанавливаем ключ значение для текущего потока
red.expire(run_key, time); // ставим установленному ключу для потока время жизни
msg.payload = await red.get(run_key);
// msg.store_key = await red.get(store_key);
return msg;
- complete
- Forming key for KeyDB command PERSIST
Код функции
let flow_key = flow.get('flow_key');// использование потоковой переменной ключ
// Работа с keyDB
let con_config_h = global.get('con_config_h'); //конфиг подключения к KeyDB хост
let con_config_p = global.get('con_config_p'); //конфиг подключения к KeyDB порт
const red = new redis(con_config_p, con_config_h); //подключение к нужному хосту и порту
msg.persist = await red.persist(flow_key); // устанавливаем ключ значение для текущего потока
let store_key = 'store:' + flow_key; //ключ для хранилища всех ключей и значений
let get_value = await red.get(store_key);
//message для информации
msg.msg = 'Поток выполнился. ИНФО: ' + get_value;
return msg;

Код потока Monitoring the execution of threads using KeyDB 1
Таблица с историей выполнения потоков
Код таблицы с историей выполнения потоков Table with thread execution history
Поток можно разворачивать и тестировать у себя на стенде
Отправка уведомлений на почту
Поток помогает отправлять уведомления на почту.

Параметры приходят на вход узлу динамически, поэтому их не нужно устанавливать.
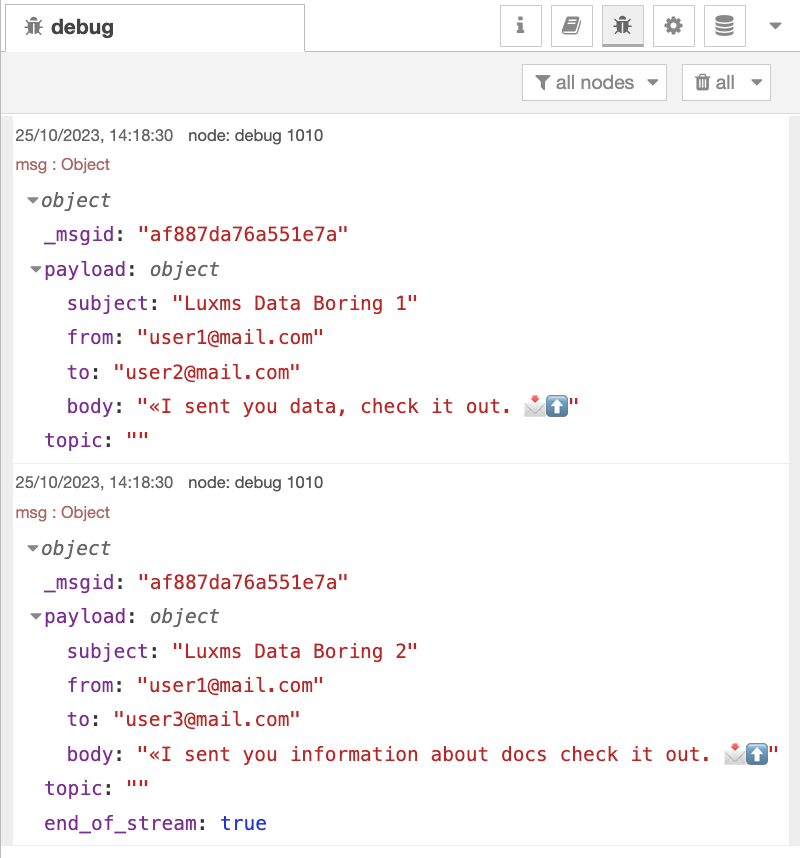
Формирование параметров в узле SQL query базы PostgeSQL, которая передаёт на вход узлу send email, приведен ниже. Данный запрос формирует два сообщения в окне debug, который позволяет отправить сигнал на вход узлу дважды.
SELECT 'Luxms Data Boring 1' AS subject
,'user1@mail.com' AS from
,'user2@mail.com' AS to
,'«I sent you data, check it out. 📩⬆️' AS body
UNION ALL
SELECT 'Luxms Data Boring 2' AS subject
,'user1@mail.com' AS from
,'user3@mail.com' AS to
,'«I sent you information about docs check it out. 📩⬆️' AS body
Результат работы узлы SQL query видим в окне debug.
Код потока Sending notifications to the mail