Luxms Data Boring представляет собой мощный и гибкий инструмент, который обеспечивает полный спектр возможностей для сбора и обработки данных.
Данный инструмент можно приобрести в качестве отдельного продукта, что предоставляет гибкость выбора и интеграции только необходимых функциональных возможностей.
Luxms BI Data Boring включен в единый реестр российских программ для электронных вычислительных машин и баз данных (Запись в реестре от 15.04.2022 №13301).
Инструмент решает следующие функциональные и технические задачи:
Высокоскоростной автоматизированный сбор данных из систем и хранилищ;
Модернизация ETL-процессов за счёт подготовки слоя горячих данных – данных, необходимых в оперативной работе;
Эффективная обработка и структурирование данных – фильтрация, группировка, агрегирование и расчёты;
Подготовка витрин данных для визуализации в BI-системе;
Автоматизация и упрощение выполнения регулярных etl-задач через графический интерфейс

Целевое использование
Приоритет хранилища – интерактивное обслуживание пользователей. Пользователей много, поэтому ресурсная квота на сложную обработку данных минимальна
Нагружать хранилище тяжёлыми запросами из BI нет возможности в силу архитектурных или производительных ограничений
Архитектура
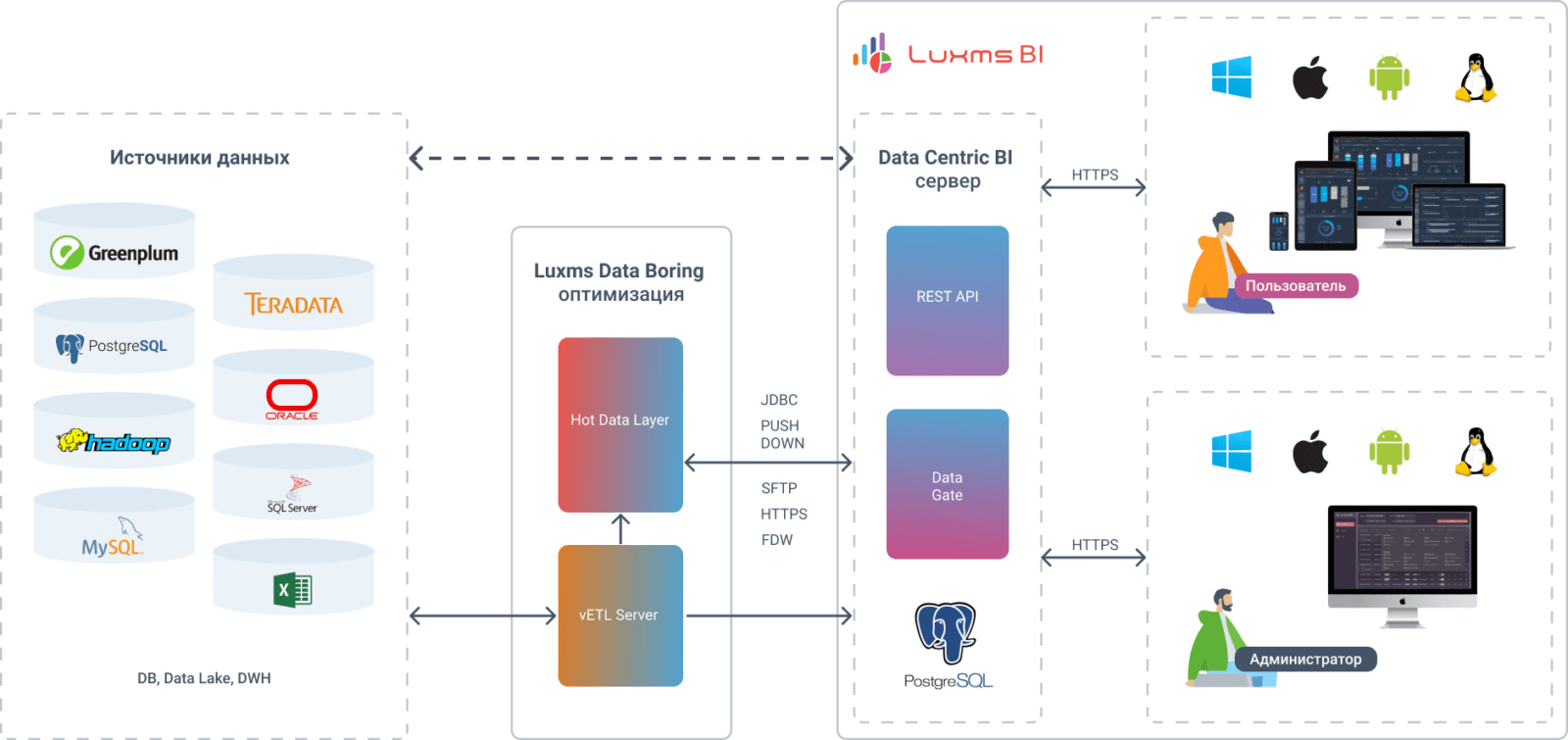
Тёплый слой: Greenplum/Arenadata DB
BI: Luxms BI
Визуальный интерфейс: Node-Red
Высокооптимизированные MPP компоненты на java для работы с Luxms BI, PostgreSQL, Kafka, ClickHouse/Arenadata Quickmarts, Greenplum/Arenadata DB
Загрузка данных в JDBC источники с оптимизацией для PostgreSQL и ClickHouse/Arenadata Quickmarts
Выполнение SQL запросов в JDBC источниках
Коннектор для Kafka
Коннектор для Redis
Коннектор для TCP/UDP сокетов
HTTP сервер и HTTP клиент
Методы машинного обучения
Математические методы любой сложности: статанализ, ML, NLP, скрипты на R/Python.
Для текстовых данных – методы NLP
Схема работы
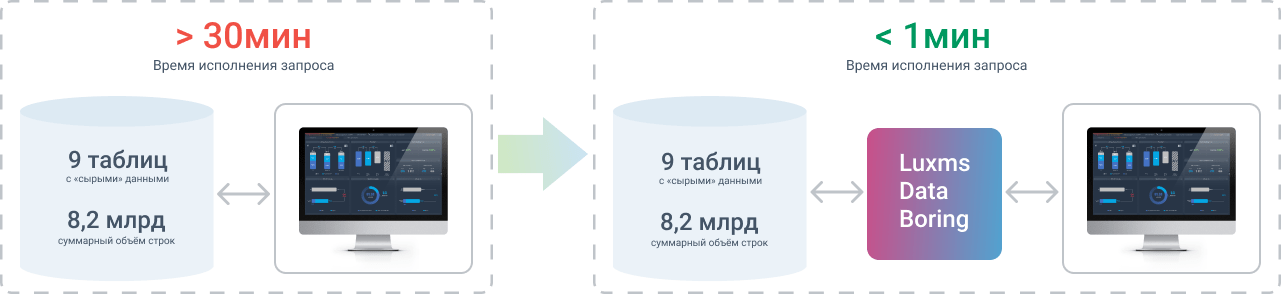
Результат апробации на реальных данных