No/Low-Code ETL/ELT-инструмент, работающий на основе потоков
В Luxms BI есть встроенный ETL/ELT-инструмент – Luxms BI Data Boring.
- Удобен когда есть много различных классов источников
- Работает как отдельный инструмент, так и в связке с любой BI-системой
- Позволяет быстро выстроить связь с разнородными источниками данных
- Быстрое прототипирование
Управление рабочим процессом
Модель программирования Data Boring на основе потоков идеально подходит для линейных рабочих процессов, включающих задачи обработки данных и автоматизации
- Пользователи могут визуально проектировать свои рабочие процессы, перетаскивая и соединяя узлы в редакторе Data Boring
- Подходит для средних проектов, быстрого прототипирования и ситуаций, когда определения рабочих процессов на основе кода могут быть слишком сложными
Доступность и удобство
Luxms Data Boring предназначен для широкой аудитории – BI-пользователи, аналитики, дата-инженеры. Визуальный интерфейс программирования и предварительно созданные узлы позволяют новичкам легко приступить к созданию рабочих процессов без обширного опыта программирования.
Расширяемость и интеграция
- Широкий спектр готовых узлов для различных сервисов и протоколов – упрощает интеграцию с популярными платформами Интернета вещей и API
- Пользователи могут создавать собственные узлы и плагины, расширяя функциональность Data Boring в соответствии со своими потребностями
- Поддержка вендора в развитии продукта. Возможность быстрого добавления коннекторов и функциональных узлов по запросу
Luxms Data Boring помогает готовить данные для эффективной скоростной визуализации, когда классические витрины DWH не удобны или не в состоянии обеспечить необходимую скорость отклика на больших данных. Инструмент решает следующие функциональные и технические задачи:
Высокоскоростной автоматизированный сбор данных из систем и хранилищ;
Модернизация ETL-процессов за счёт подготовки слоя горячих данных – данных, необходимых в оперативной работе;
Эффективная обработка и структурирование данных – фильтрация, группировка, агрегирование и расчёты;
Подготовка витрин данных для визуализации в BI-системе;
Автоматизация и упрощение выполнения регулярных etl-задач через графический интерфейс

Целевое использование
Приоритет хранилища – интерактивное обслуживание пользователей. Пользователей много, поэтому ресурсная квота на сложную обработку данных минимальна
Нагружать хранилище тяжёлыми запросами из BI нет возможности в силу архитектурных или производительных ограничений
Архитектура
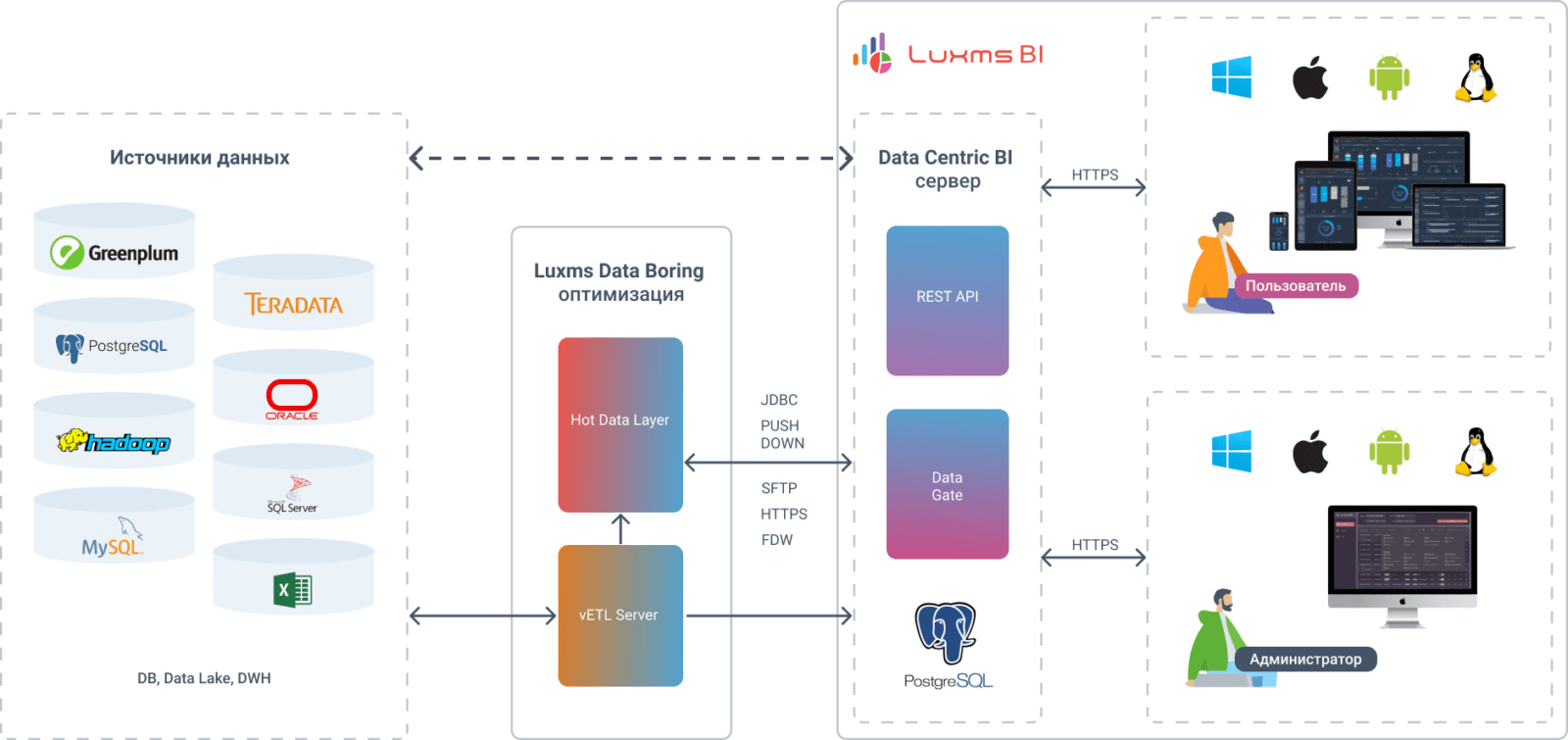
Тёплый слой: Greenplum/Arenadata DB
BI: Luxms BI
Визуальный интерфейс: Node-Red
Высокооптимизированные MPP компоненты на java для работы с Luxms BI, PostgreSQL, Kafka, ClickHouse/Arenadata Quickmarts, Greenplum/Arenadata DB
Загрузка данных в JDBC источники с оптимизацией для PostgreSQL и ClickHouse/Arenadata Quickmarts
Выполнение SQL запросов в JDBC источниках
Коннектор для Kafka
Коннектор для Redis
Коннектор для TCP/UDP сокетов
HTTP сервер и HTTP клиент
Методы машинного обучения
Математические методы любой сложности: статанализ, ML, NLP, скрипты на R/Python.
Для текстовых данных – методы NLP
Схема работы
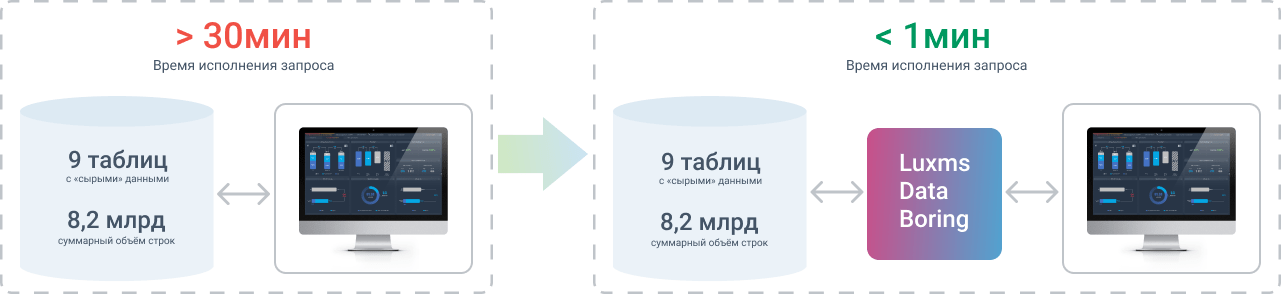
Результат апробации на реальных данных