Интеграция с Jupyter Notebook для отображения прогнозируемых данных в Luxms BI
Данный функционал представлен на текущий момент в бета-режиме. Мы будем рады услышать обратную связь и доработать функционал в соответствии с вашими требованиями.
Подключение моделей из Jupyter Notebook
В Luxms BI предусмотрена возможность интеграции с моделями обработки данных и прогнозной аналитики, рассчитанных в Jupyter Notebook. В данном разделе описана только реализация с Luxms BI, без подробностей развертывания самого Jupyter Notebook и постороения моделей обработки данных.
Для передачи данных из Jupyter Notebook в Luxms BI необходидимо использовать бибилиотеку Flask server. Данный сервер будет запущен на порту 8088.
Рекомендуем разворачивать Jupyter Notebook на том же узле, где развернут LuxmsBI-web во избежание проблем с коннектом.
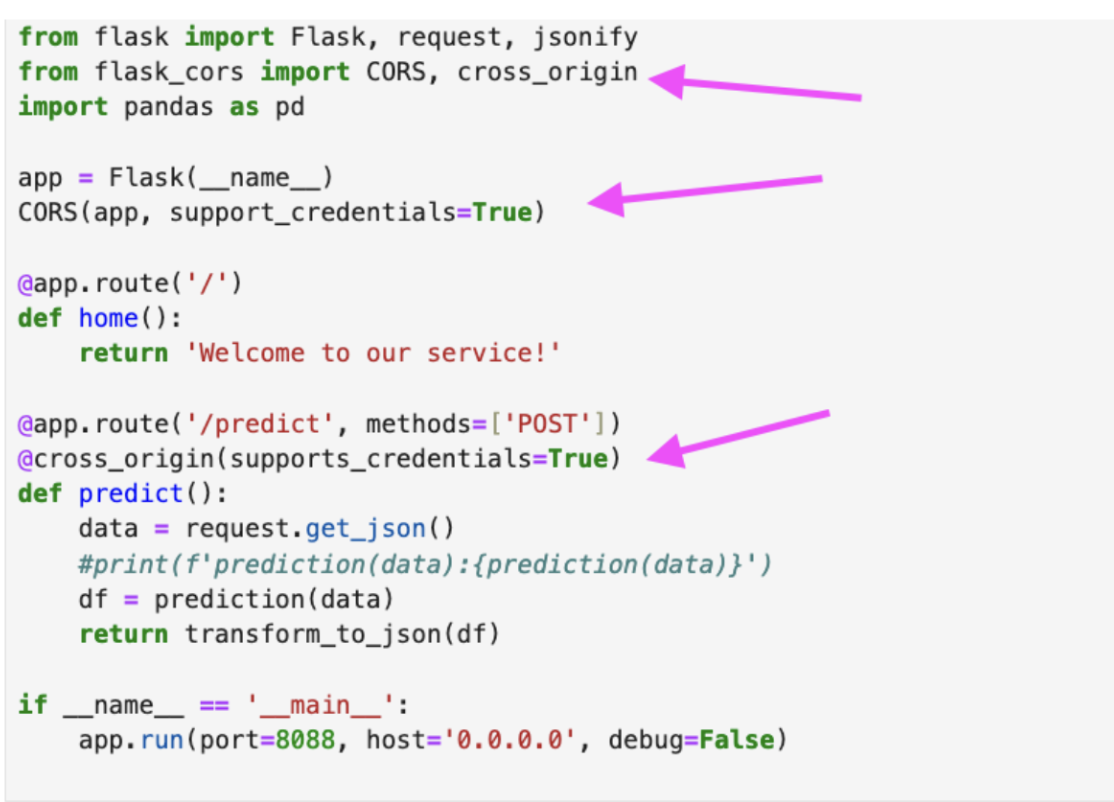
С помощью POST запроса /predict с интерфейса bi отправляются данные в формате json. В функции predict входящий json записывается в переменную data. Функция predict возвращает результат предсказания в формате json. Для этого функция prediction преобразует данные и передает их модели. Функция transform_to_json преобразует тип данных в json и возвращает данные в response POST запроса. Ниже представлен пример такого кода:
from flask import Flask, request, jsonify
from flask_cors import CORS, cross_origin
import pandas as pd
app = Flask(__name__)
CORS(app, support_credentials=True)
@app.route('/')
def home():
return 'Welcome to our service!'
@app.route('/predict', methods=['POST'])
@cross_origin(supports_credentials=True)
def predict():
data = request.get_json()
df = prediction(data)
return transform_to_json(df)
if __name__ == '__main__':
app.run(port=8088, host='0.0.0.0', debug=False)
В функцию prediction передается json (исходные данные, которые пришли из bi), преобразовали в объект DataFrame (многомерная таблица объект pandas - библиотеки python), затем вызывается функция fit_data:
#передается в след функцию dataframe и отдается наружу результат предсказания (сами значения forecast и доверительные интервалы)
def prediction(dt):
df = pd.DataFrame.from_dict(dt)
result = fit_data(df)
return result
Функция fit_data выполняет преобразования DataFrame таблицы для корректной работы модели, тип данных столбца dt необходимо преобразовать в datetime и преобразовать его в индекс. Далее необходимо вызывать функцию predict_result, в которую передаем преобразованную ранее таблицу.
def fit_data(df):
df['dt'] = pd.to_datetime(df['dt'])
df = df.set_index('dt')
return predict_result(df)
Функция predict_result создает модель и предсказывает данные.
Для этого создается модель SARIMAX (из библиотеки statsmodels), параметры которой (p,d,q,P,D,Q,s) были рассчитаны ранее на тренировочных данных (исходя из минимального значения параметра AIC). Далее модель оптимизируется под переданный DataFrame df, а в объект prediction передаются результаты предсказания (в данном случае step = 2 предсказания будут для двух временных точек). Результат получаем в виде столбцов mean_prediction - среднее предсказание (можно представить как 50-й перцентиль), верхнюю и нижнюю границу доверительного интервала (conf_int).
def predict_result(df):
model = SARIMAX(df, order=(1, 1, 1), seasonal_order=(0, 1, 1, 12))
results = model.fit()
predictions = results.get_forecast(steps=24)
mean_prediction = predictions.predicted_mean
print(f'mean_prediction: {mean_prediction}')
ci_95 = predictions.conf_int(alpha=0.05)
result_df = pd.DataFrame({
'Forecast': mean_prediction,
'Lower CI': ci_95.iloc[:, 0],
'Upper CI': ci_95.iloc[:, 1]
})
return result_df
В функции predict_result можно использовать и другие модели. Подбор коэффициентов и выбор модели остается на усмотрение Data-scientist’а.
Результаты предсказания (таблица result_df) сохраняются в df функции predict (см выше), передаются функции transform_to_json, которая преобразует данные объекта pandas в json объект - result. result возвращается функцией predict и приходит в ответе POST запроса /predict.
Для корректной работы в bi необходимо добавить опцию cross origin, в противном случае браузер не даст сделать запрос за данными.
При использовании вышеописанного алгоритма будут использоваться только данные, которые представлены в веб-интерфейсе Luxms BI. Для использования данных куба, вы можете воспользоваться Luxms BI API с использованием jwt-токена и запрашивать данные напрямую через куб.
Отображение прогнозных данных в дэше Luxms BI
Для того, чтобы отобразить в дэше прогнозируемые данные, рассчитанные в Jupyter Notebook, необходимо в конфигурации дэша указать блок forecast со следующим содержимым:
forecast: {
url: 'http://<сервер_с_jupyter_notebook>:8088/predict',
steps: 24,
algorithm: 'CUSTOM',
},
где
- url - ссылка на сервер, где развернут Flask-сервер. Обязательно в конце должно быть указано /predict
- steps - количество отображаемых шагов. Должно быть указано значение, меньшее или равное количеству шагов, рассчитанных в Jupyter Notebook;
- algorithm - для рассматриваемого случая значение всегда ‘CUSTOM’.
После настройки сервера, рассчета прогнозных данных и указания блока forecast дэш будет отображен следующим образом:
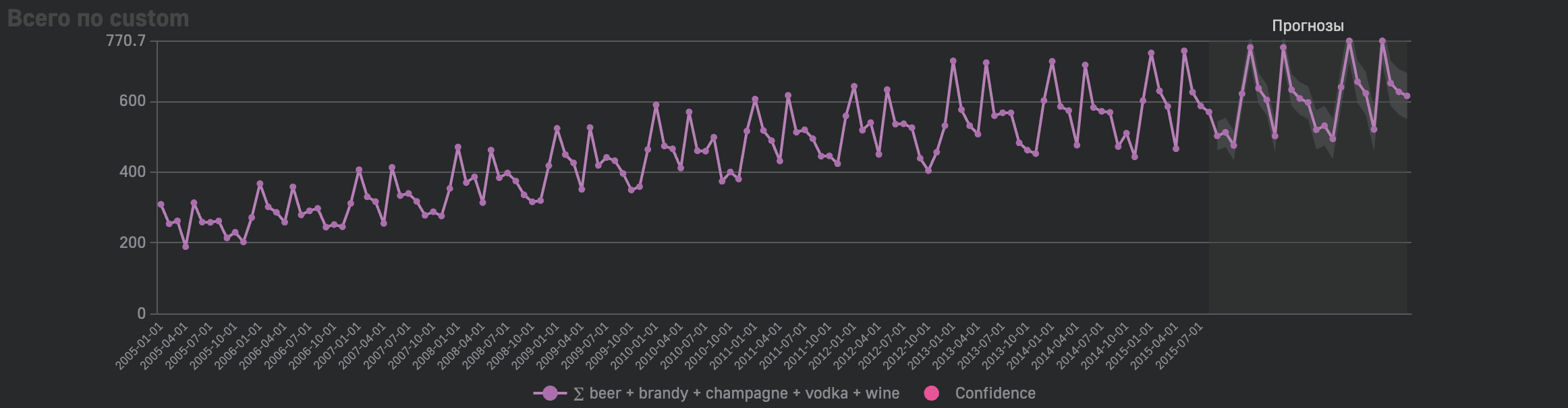
Отображение jupyter notebook как дэшборд в Luxms BI
Для отображения jupyter notebook внутри bi вам необходимо в конфигурацию jupyter notebook указать следующий параметр:
c.ServerApp.disable_check_xsrf=True
И запустить сам проект со следующими параметрами:
jupyter-lab --config=./jupyter_notebook_config.py --ip=0.0.0.0
где в ключе config необходимо указать путь до конфигурационного файла jupyter notebook.
Без вышеописанных настроек jupyter notebook не будет отображаться в дэше “Внешний” внутри Luxms BI
вы можете воспользоваться дэшем “Внешний” указав ссылку на сервер. Ниже представлен пример такого дэша:
{
url: 'http://<сервер_с_jupyter_notebook>:8888/lab',
frame: {
h: 8,
w: 12,
x: 0,
y: 0,
},
dataSource: {
koob: '',
},
dashboard_id: 0,
title: '',
description: null,
view_class: '/external',
}